Déployer un réseau de neurones artificiels convolutionnels sur un système embarqué
Introduction
L’essor des plateformes embarquées capables de traitement IA a profondément changé la donne : il est désormais possible de déployer des solutions intelligentes sur l’équipement lui-même, sans dépendre du cloud. C’est ce qu’on appelle l’« edge AI ».
Lors d’un récent projet, nous avons exploré comment déployer un système de détection d’objets en temps réel à l’aide d’un modèle de vision par ordinateur sur une carte Verdin NXP i.MX 8M Plus, une cible populaire grâce à son unité de traitement neuronal (NPU) intégrée.
Cet article partage notre retour d’expérience technique : depuis la conversion des modèles jusqu’à leur intégration dans une image Yocto, en passant par les compromis nécessaires pour atteindre des performances en temps réel avec des résultats satisfaisants.
Contexte et objectif
ICOR Technology conçoit et fabrique des robots, outils et équipements innovants et de haute qualité pour les communautés EOD et SWAT à travers le monde. Les utilisateurs peuvent piloter les robots ICOR à distance via une unité de commande et de contrôle, qui affiche en temps réel les flux vidéo provenant des caméras du robot.
L’objectif du projet était de concevoir une démonstration de navigation robotique assistée par la vision, reposant sur un modèle de détection d’objets en temps réel comme le montre le schéma ci-dessous.
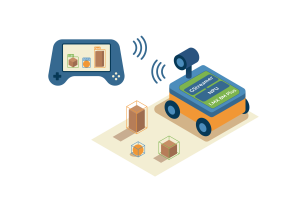
Les principaux objectifs étaient :
- Traitement à 30 images par seconde
- Exécution sur une cible embarquée basse consommation
- Usage d’un modèle pré-entraîné de type YOLOv8 (You Only Look Once)
- Détection d’objets génériques (personnes, chaises, etc…), détection de visages et détection d’éléments de navigation (portes, escaliers, fenêtres)
- Intégration complète dans une image Linux Yocto
Nous avons choisi de travailler avec le System on Module (SoM) Verdin i.MX 8M Plus, qui combine CPU, GPU, VPU et NPU dans un format adapté aux applications industrielles.
Plateforme matérielle
Le Verdin NXP i.MX 8M Plus, co-développé par NXP et intégré sur une carte conçue par Toradex, offre un bon compromis pour le traitement de l’IA embarquée :

- CPU : 4 cœurs Cortex-A53 à 1.8 GHz
- GPU : Jusqu’à 16 GFLOPS
- NPU : Jusqu’à 2.3 TOP/s
- VPU : Encodeur/décodeur matériel pour la vidéo (H.264/H.265)
Ce matériel permet d’accélérer les inférences IA, tout en restant dans les contraintes d’encombrement, de dissipation thermique et de consommation des systèmes embarqués.
TensorFlow et TensorFlow Lite

TensorFlow est une bibliothèque open source développée par Google, largement utilisée dans le domaine du machine learning et de l’intelligence artificielle. Elle fournit une infrastructure complète pour l’entraînement et le déploiement de modèles de réseaux de neurones, avec un large écosystème d’outils et de ressources qui en font une référence pour la recherche comme pour l’industrie.
TensorFlow Lite (TFLite) est une déclinaison de TensorFlow spécialement conçue pour les environnements contraints comme les systèmes embarqués et les appareils mobiles. Il permet d’exécuter des modèles optimisés en réduisant leur taille et leur consommation de ressources, tout en profitant d’accélérations matérielles (GPU, NPU, DSP).
Yocto

Yocto Project est un projet open source qui fournit un ensemble d’outils, de scripts et de couches pour construire des systèmes Linux embarqués personnalisés. Yocto permet de créer des images Linux embarquées optimisées pour des matériels spécifiques. Cela en fait un outil de référence pour les environnements contraints, où l’optimisation de la taille, des performances et de la sécurité est essentielle.
Intégration de TensorFlow Lite dans Yocto
L’environnement Yocto, bien que flexible, demande une configuration rigoureuse pour supporter les bibliothèques de Machine Learning. Voici les étapes clés que nous avons suivies :
- Base BSP Toradex : fournie pour le SoM utilisé
- Ajout de la couche meta-imx-ml : elle fournit les recettes pour
tensorflow-lite, etc. - Dépendances nécessaires :
opencv, python3-numpy, etc. - Configuration de l’image : inclusion des paquets nécessaires dans
local.conf ou un fichier .bbappend - Résolution de conflits : les couches Yocto pour l’IA ne sont pas toujours alignées, un certain travail d’intégration est requis.
En effet, dans les systèmes embarqués, les versions des packages sont fixées. Cependant certains packages peuvent partager des dépendances mais avec des versions différentes, qu’il faut donc résoudre.
Conversion et quantification du modèle
Le modèle de détection utilisé YOLOv8 a été entraîné avec Ultralytics. Nous avons choisi YOLOv8 car c’était un modèle d’architecture à l’état de l’art lorsque nous avons commencé ce projet. Il est développé sous PyTorch, puis nous avons converti en modèle TensorFlow Lite afin d’être compatible avec le NPU du i.MX 8M Plus. La version utilisée était la Nano, la plus légère de la gamme, choisie afin de respecter la contrainte de temps réel.
Étapes de conversion :
- Conversion
.pt (PyTorch) → .onnx (Open Neural Network Exchange) → .tflite(TensorFlow Lite) - Quantification en int8 : la quantification réduit la taille mémoire des modèles et accélère considérablement leur exécution, tout en assurant leur compatibilité avec le NPU.
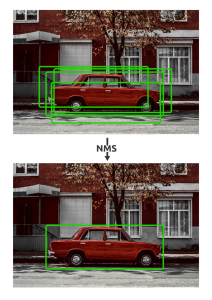
- Certaines opérations du modèle original n’étant pas supportées dans le format TFLite, nous avons dû implémenter manuellement les étapes de prétraitement et de post-traitement, notamment le Non-Maximum Suppression (NMS) comme démontré dans le schéma ci-dessous.
Le réseau de neurones produit plusieurs détections potentielles pour un même objet. L’algorithme de NMS élimine les détections redondantes en retenant la proposition avec le score de confiance le plus élevé.
💡 Le NPU du i.MX 8M Plus n’accepte que les modèles entièrement quantifiés (full integer). Il est donc nécessaire de calibrer les modèles pour assurer leur exécution sur l’accélérateur matériel.
Stratégie multi-réseaux et sélection des résolutions
Notre application devait couvrir trois tâches de détection distinctes :
- Détection d’objets génériques avec le dataset COCO
- Détection d’éléments de navigation (portes, escaliers, fenêtres) à partir d’un dataset spécialisé
- Détection de visages à partir d’un dataset d’identification faciale
Une première approche centralisée…
Dans un premier temps, nous avons tenté d’entraîner un réseau unique combinant les trois datasets. Cette approche, bien que séduisante sur le papier, a rapidement montré ses limites en termes de performance. Les raisons sont multiples :
- Incohérences dans les conventions d’annotation entre datasets
- Nature hétérogène des images (scènes intérieures, visages, objets du quotidien)
- Déséquilibre dans la distribution des labels, certains étant largement sous-représentés
Ci-dessous nous pouvons voir :
- un exemple d’image du dataset de segmentation de COCO avec son annotation : les pixels des objetcs sont colorés dans leur contour.
- un montage de plusieurs images du dataset de visages : un visage est une image du dataset et son annotation correspond à toute l’image.


Vers une approche multi-réseaux spécialisés
Pour contourner ces limitations, nous avons opté pour une solution plus modulaire : un réseau de neurones distinct pour chaque tâche, chacun optimisé avec une résolution adaptée. C’était une approche audacieuse, car exécuter trois réseaux de neurones distincts sur un système embarqué limité en ressources constitue un véritable défi technique. Et pourtant, nous avons réussi à le faire fonctionner efficacement en temps réel Notre approche rappelle également le concept d’une architecture Mixture of Experts, où différents modèles spécialisés contribuent à résoudre différents aspects d’un problème. Voici les dimensions que nous avons choisies pour les différents jeux de données :
- COCO : réseau quantifié à 320×320
- Navigation (portes, escaliers, fenêtres) : 160×160
- Visages : également à 160×160
Ce choix nous a permis d’obtenir des résultats très satisfaisants, tout en réduisant la charge de calcul. Le tableau et le graphique suivants résument les performances mesurées selon la résolution.
Résultats de performance
| Résolution | Temps (ms/image) | FPS estimé | Précision | Rappel | F1-score |
|---|
| 640×640 | 58 ms | 17.2 fps | 89.5% | 28.2% | 0.429 |
| 480×480 | 34 ms | 29.4 fps | 90.6% | 25.7% | 0.400 |
| 320×320 | 15.5 ms | 64.5 fps | 91.5% | 20.7% | 0.338 |
| 160×160 | 5.3 ms | 188.7 fps | 90.6% | 10.0% | 0.180 |
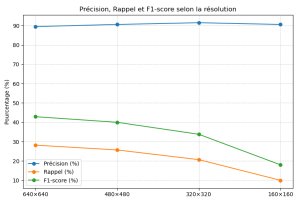
Comme on peut le voir dans le tableau et sur le graphique, les résolutions plus faibles permettent un traitement ultra-rapide (faible temps d’inférence ou haut nombre de FPS), ce qui les rend idéales pour des réseaux spécialisés sur des tâches précises, où la perte de précision reste acceptable.
Conclusion
Dans ce projet, nous avons intégré TensorFlow Lite dans Yocto en résolvant les conflits de dépendances, exploré une approche multi-réseaux pour spécialiser les tâches de détection, et optimisé la résolution afin de trouver le meilleur compromis entre vitesse et précision. Nous n’avons pas seulement déployé un seul modèle, mais trois réseaux de neurones spécialisés sur un système embarqué tout en repectant la contrainte temps réel (30 fps), démontrant ainsi le potentiel de l’IA embarquée appliquée au monde réel.
Cette expérience montre que la vision intelligente embarquée est réalisable sur des plateformes à ressources limitées, à condition de bien maîtriser les outils, des frameworks IA aux couches Yocto.
Nous croyons que ce type d’intégration entre systèmes Linux embarqués et IA représente une voie prometteuse pour l’avenir de l’automatisation, de la robotique et de l’industrie en général.






