Entraînement de YOLO pour la Détection Temps Réel sur Système LiDAR
Il s’agit du deuxième volet d’une série en trois parties consacrée à la détection temps réel sur système LiDAR. Retrouvez ici l’article 1 sur la génération de jeux de données synthétiques de profondeur et NIR.
Actuellement, de nouveaux LiDAR embarqués à basse résolution, tels que le VL53L9CX, émergent comme une option particulièrement adaptée pour la détection temps réel sur système LiDAR. Cette matrice de 54 × 42 pixels fournit simultanément des données de profondeur basse consommation, d’infrarouge et d’illumination active. Dans ce contexte, l’intégration d’un modèle YOLO optimisé permet de transformer ces signaux pour la détection temps réel sur système LiDAR.
Nous commençons cet article par une brève introduction à YOLO. Nous menons ensuite une étude exploratoire évaluant la précision de YOLO sur plusieurs jeux de données. L’objectif est d’analyser l’impact des différentes modalités d’image. Les expériences d’entraînement ont été réalisées à partir d’entrées de profondeur relative, de profondeur absolue, de proche infrarouge (NIR) et multimodales (profondeur + NIR). Pour les détails concernant la génération de ces jeux de données, nous renvoyons le lecteur à l’article 1 de cette série. Enfin, nous abordons l’optimisation des hyperparamètres de YOLO afin d’obtenir les meilleures performances possibles compte tenu des caractéristiques des données d’entrée.
Introduction à YOLO et YOLOv8 : vision par ordinateur en temps réel
Dans le domaine de la vision par ordinateur, YOLO (You Only Look Once) a fondamentalement transformé la manière dont les machines perçoivent le monde visuel. Plus précisément, YOLO remplace les pipelines multi-traitements par une seule étape. Il effectue simultanément la proposition de régions d’intérêts et la classification. Par conséquent, cette architecture « one-shot » permet une inférence extrêmement rapide. Elle rend la détection temps réel sur système LiDAR possible.
L’évolution vers YOLOv8
YOLOv8, publié par Ultralytics en 2023, demeure l’état de l’art en matière d’équilibre entre précision et efficacité. Nous utilisons YOLOv8 plutôt que des versions plus récentes comme YOLO11 en raison de son meilleur support sur le matériel industriel, en particulier sur les plateformes NPU.
YOLOv8 introduit plusieurs améliorations architecturales clés :
- Architecture sans ancres : contrairement aux versions précédentes de YOLO, YOLOv8 prédit directement les centres des objets sans s’appuyer sur des boîtes d’ancrage prédéfinies. Cela améliore significativement la précision de détection, en particulier pour les silhouettes humaines aux postures et échelles variées.
- Backbone C2f : le module Cross-Stage Partial Bottleneck (C2f) améliore le flux de gradients tout en réduisant la complexité du modèle. Il en résulte des modèles plus légers avec de meilleures performances.
- Polyvalence native des tâches : au-delà de la détection de boîtes englobantes, YOLOv8 prend en charge nativement la segmentation d’instances et l’estimation de pose. Il offre ainsi une voie claire vers des tâches de perception et d’analyse comportementale plus avancées.
En résumé, YOLOv8 atteint une efficacité de Pareto supérieure en termes de latence-mAP lorsque l’on considère les jeux de données et l’exécution sur des plateformes embarquées. Cela le rend parfaitement adapté à la détection temps réel sur système LiDAR pour l’Edge AI.
Stratégies d’entraînement pour la détection en temps réel sur système LiDAR
Deux stratégies sont comparées afin de déterminer la meilleure approche pour un déploiement embarqué à haute performance. La stratégie 1 repose sur un mélange d’experts (Mixture of Experts, MoE). La stratégie 2 utilise un entraînement multimodal à modèle unique.
Stratégie 1 : Mixture of Experts (MoE)
Une approche Mixture of Experts (MoE) utilise deux modèles YOLOv8 parallèles, respectivement spécialisés sur les données de profondeur et de NIR. D’un point de vue méthodologique, cette stratégie est plus simple, chaque modèle étant optimisé pour une seule modalité.
Néanmoins, elle soulève plusieurs questions critiques. Premièrement, chaque modalité fournit-elle suffisamment d’informations discriminantes à ultra-basse résolution pour fonctionner de manière indépendante ? Deuxièmement, les architectures embarquées basse consommation peuvent-elles supporter des pipelines d’inférence concurrents avec des contraintes strictes de latence, de puissance et de mémoire ?
Stratégie 2 : entraînement multimodal à modèle unique
La seconde approche consiste à entraîner un seul modèle YOLOv8 sur des images d’entrée multimodales. Alors que les images RGB conventionnelles comportent trois canaux, nos entrées n’en contiennent que deux : la profondeur et le proche infrarouge (NIR). La mise en œuvre de cette stratégie implique de fusionner les modalités dans un nouveau jeu de données et d’adapter la chaîne d’entraînement à des représentations d’entrée personnalisées.
Le principal défi réside dans la capacité de généralisation du réseau à partir d’un entraînement avec cette modalité non conventionnelle. Toutefois, un pipeline à modèle unique réduit considérablement la charge de calcul et simplifie l’inférence sur des systèmes embarqués aux ressources limitées. Ce dernier point est significatif pour de la détection temps réel sur système LiDAR.
Vue d’ensemble des résultats expérimentaux
Nous présentons les résultats des entraînements suivants avec YOLOv8 sur trois jeux de données :
- NIR, généré par inférence à l’aide du modèle Pix2Next.
- Profondeur, produit par inférence à partir du modèle ZoeDepth.
- Multimodal, où chaque image inclut simultanément des canaux de profondeur et de NIR.
Dans ce contexte, plusieurs variantes ont été évaluées selon ces stratégies. Nous avons comparé YOLOv8 et YOLO11 en entraînement from scratch et avec des poids pré-entraînés RGB (transfer learning). En outre, nous avons utilisé les topologies nano (n), small (s) et medium (m).
Le tableau suivant récapitule les modèles testés et met en évidence leurs performances de référence sur des images d’entrée en 640×640. Alors que le mAP val 50–95 mesure la qualité et la cohérence de la détection, le nombre de paramètres et les FLOPs estiment le coût d’inférence. Toutefois, ces métriques nécessitent une contextualisation pour le déploiement sur NPU et les optimisations spécifiques au matériel pour de la détection temps réel sur système LiDAR.
| Modèle | Résolution (pixels) | mAP val 50–95 | Latence CPU ONNX (ms) | Latence A100 TensorRT (ms) | Paramètres (M) | FLOPs (B) |
|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLO11n | 640 | 39.5 | 56.1 ± 0.8 | 1.5 ± 0.0 | 2.6 | 6.5 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLO11s | 640 | 47.0 | 90.0 ± 1.2 | 2.5 ± 0.0 | 9.4 | 21.5 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLO11m | 640 | 51.5 | 183.2 ± 2.0 | 4.7 ± 0.1 | 20.1 | 68.0 |
Optimisation de l’entraînement : sélection et interprétation des bonnes métriques
Pour commencer, une évaluation complète des performances de YOLOv8 nécessite une approche multi-métriques plutôt que de s’appuyer sur un seul indicateur. L’objectif est d’optimiser le compromis entre la précision de localisation et la sensibilité de détection. Cela nous permettra d’ajuster efficacement l’entraînement de YOLO pour la détection temps réel sur système LiDAR.
Premièrement, les principales métriques de détection utilisées sont la précision et le rappel. La précision et le rappel constituent les métriques fondamentales de l’analyse de performance.
- Précision : quantifie la fiabilité du modèle en mesurant le ratio de détections correctes par rapport au nombre total de prédictions (minimisation des faux positifs).
- Rappel : mesure la sensibilité en calculant la proportion d’objets réels détectés avec succès. Un faible rappel reflète donc un nombre élevé de faux négatifs, lorsque le modèle ne détecte pas des objets existants.
En outre, le score F1 est la moyenne harmonique de la précision et du rappel. Il est particulièrement utile pendant l’entraînement, car il synthétise la performance globale en une seule valeur. Si le score F1 plafonne alors que la précision continue de s’améliorer, cela indique souvent une baisse du rappel. Cette information est précieuse pour ajuster le seuil de confiance afin de rééquilibrer précision et rappel.
Deuxièmement, une métrique spécifique à la détection d’objets est le mAP (mean Average Precision), qui constitue la référence standard pour comparer les modèles de détection. Il est calculé comme l’aire sous la courbe précision-rappel.
- MAPval 50 mesure la précision moyenne avec un seuil d’Intersection over Union (IoU) de 0,5. Elle reflète principalement la capacité du modèle à détecter les objets à un niveau grossier.
- MAPval 50-95 est une métrique stricte qui moyenne le mAP sur des seuils d’IoU allant de 0,5 à 0,95 ; des scores élevés reflètent un meilleur alignement des boîtes englobantes avec la vérité terrain.
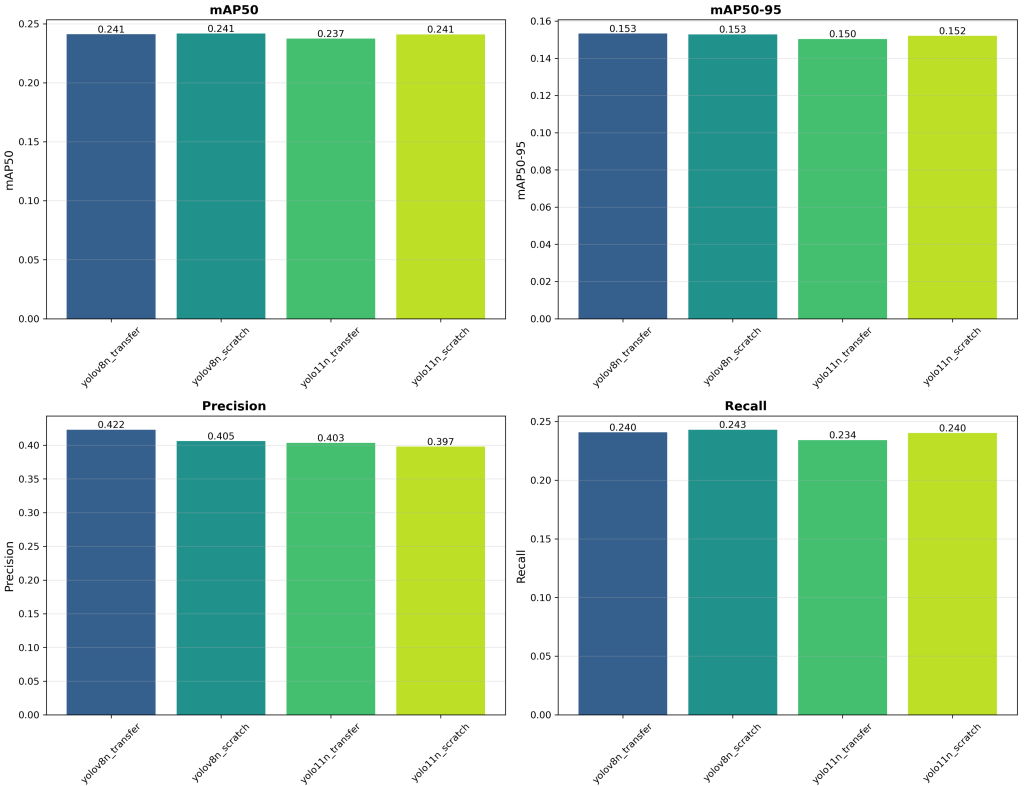
YOLO sur le jeu de données NIR
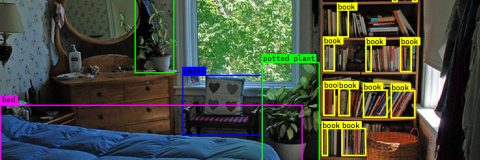
Les premières expériences d’entraînement ont été menées sur un jeu de données comprenant 10 classes : [‘person’, ‘bench’, ‘backpack’, ‘bottle’, ‘cup’, ‘chair’, ‘tv’, ‘laptop’, ‘cell phone’, ‘book’].
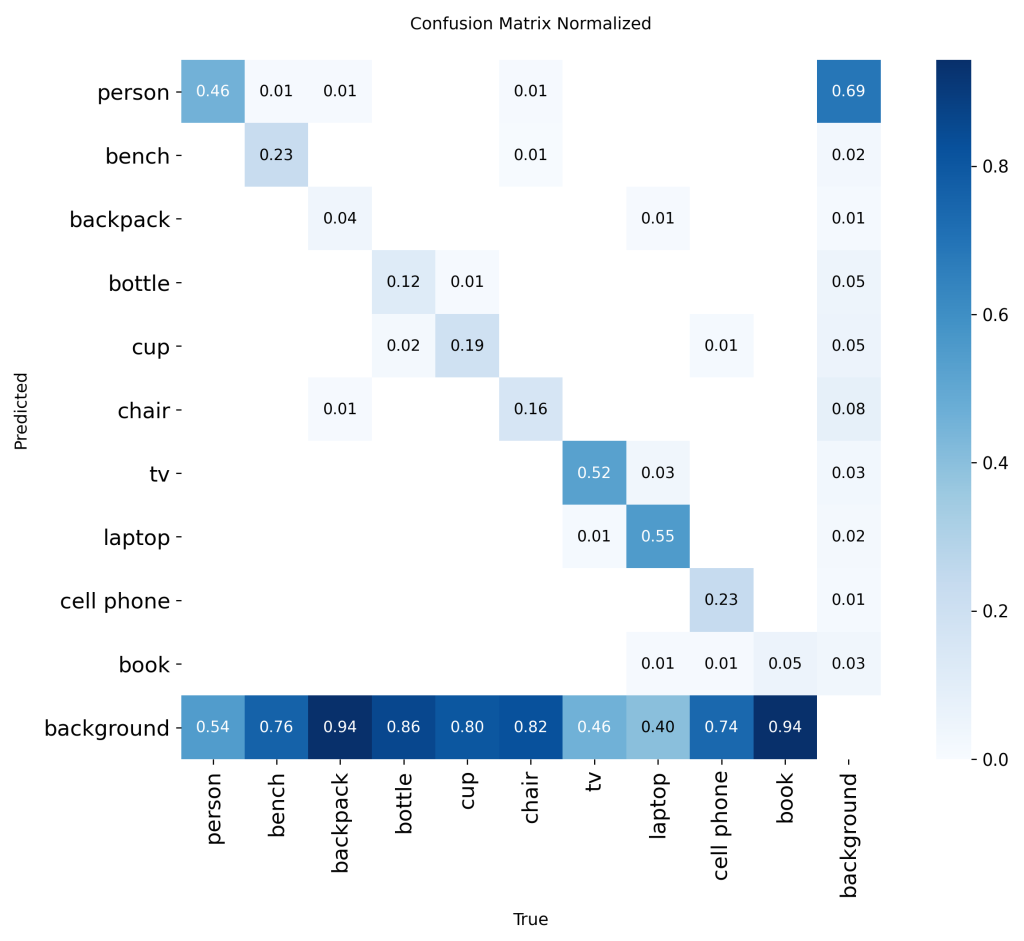
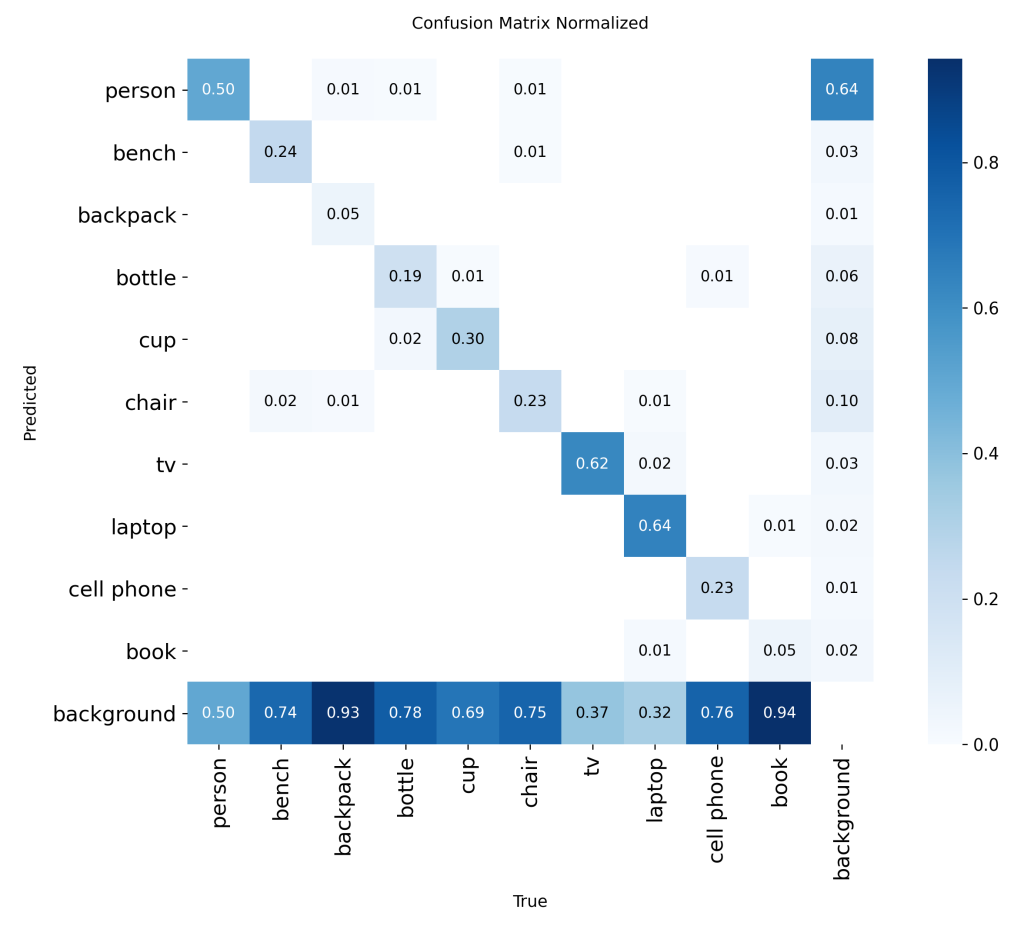
Malheureusement, la détection a été limitée par la modalité NIR et par la faible résolution d’entrée de 54×42. En conséquence, les MAPval 50-95 et MAPval 50 présentent de faibles performances pour cette modalité. De plus, la précision et le rappel sont également très bas, ce qui indique un taux élevé de faux positifs et de faux négatifs. Une analyse complémentaire à l’aide de la matrice de confusion normalisée fournit une vision plus fine des capacités de détection par classe du modèle. Elle met en évidence les classes les plus affectées et les zones de mauvaise classification. La matrice de confusion normalisée présentée correspond à un modèle YOLOv8s entraîné from scratch, servant de référence pour les améliorations ultérieures.
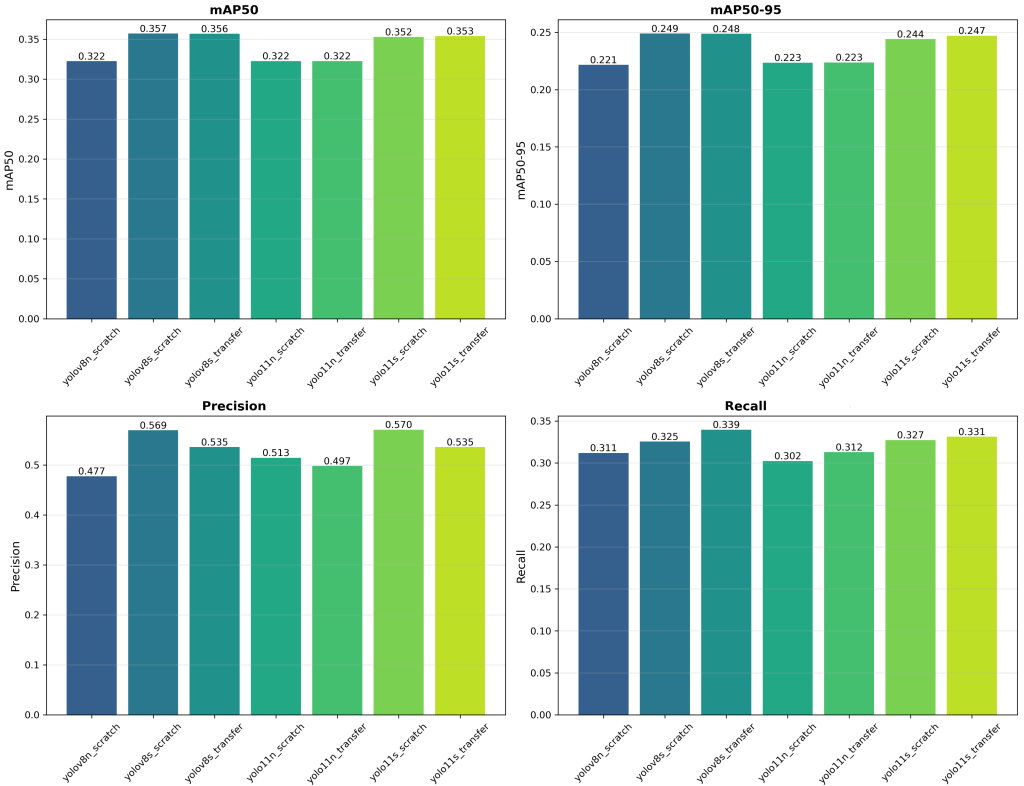
YOLOv8 sur le jeu de données de profondeur
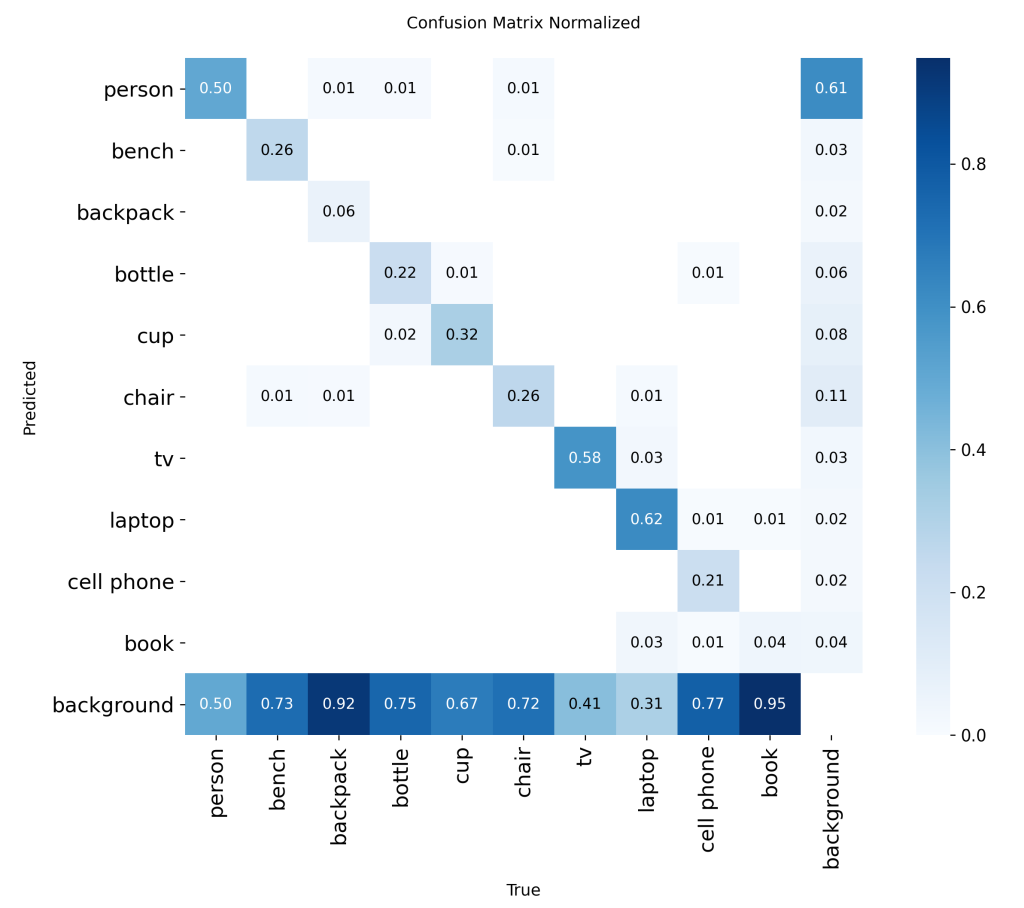
Bien que la modalité NIR produise de meilleurs résultats de détection, les performances globales des modèles demeurent insuffisantes. Le MAPval 50-95 ne dépasse pas 0,25. La matrice de confusion présentée ci-dessus correspond à un modèle YOLOv8s entraîné from scratch sur le jeu de données de profondeur. Ces résultats préliminaires montrent qu’une approche MoE est difficilement optimisable pour la détection temps réel sur système LiDAR avec YOLO.
YOLOv8 sur un jeu de données multimodal
À la suite de ces premiers résultats d’entraînement, nous avons décidé d’abandonner le transfert d’apprentissage. Nous nous sommes concentrés sur l’entraînement des modèles from scratch. Les différences de performance étant marginales, nous avons cherché à spécialiser le modèle sur les modalités profondeur et NIR. En raison des faibles performances en mono-modalité, nous avons mis en place une fusion Depth-NIR à deux canaux pour l’entrée de YOLOv8. Cette représentation multimodale enrichit les données d’entrée avec des caractéristiques complémentaires. L’objectif final étant d’améliorer la performance de la détection temps réel sur système LiDAR.
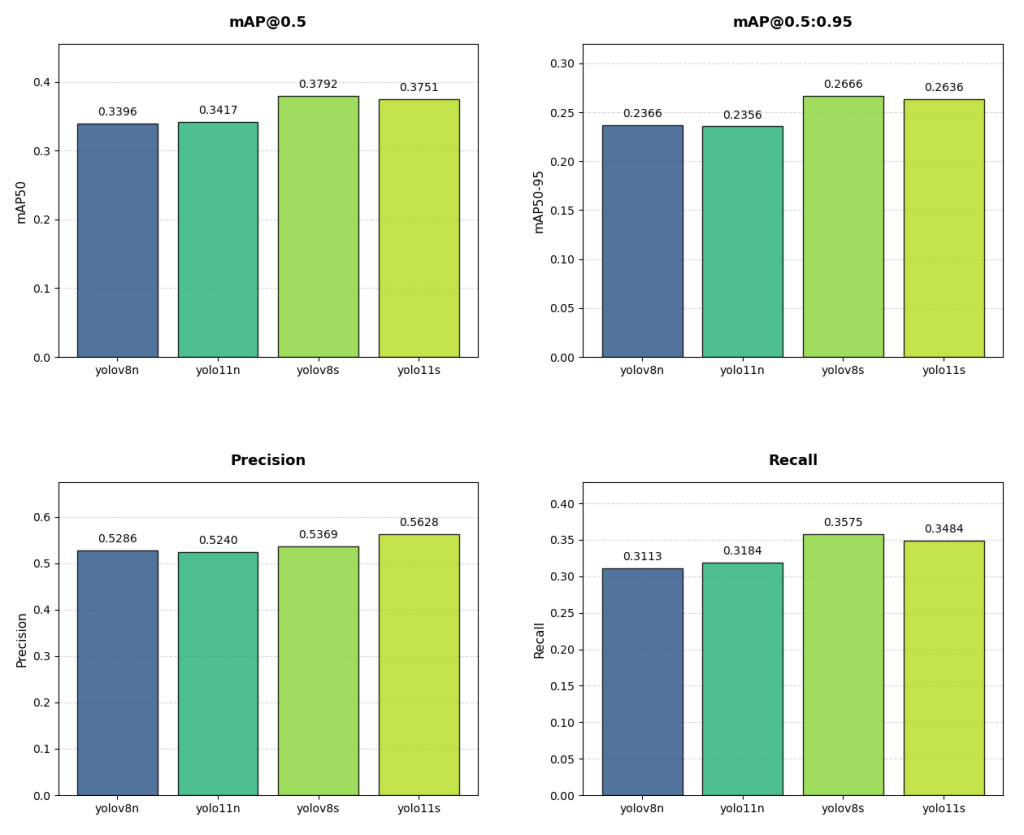 |  |
Malgré l’entraînement sur deux modalités afin d’enrichir les caractéristiques extraites, les résultats ne sont pas encore satisfaisants. Actuellement, la différence de performance entre YOLOv8 et YOLOv11 n’est pas significative. En conséquence, nous avons privilégié le modèle offrant les meilleures performances sur le matériel cible, à savoir YOLOv8. Étant donné que YOLOv11 n’apporte aucun gain significatif en précision, la perte associée en efficacité matérielle n’est pas justifiée. Pour la détection temps réel sur système LiDAR pour l’Edge AI, les contraintes matérielles sont déterminantes et doivent être prises en compte dès les premières étapes.
De plus, certaines classes, telles que book et backpack, sont à peine détectées. La faible résolution et les contraintes de modalité empêchent une caractérisation fiable des objets. Par conséquent, nous avons décidé de réduire le périmètre de la tâche et de nous concentrer exclusivement sur la détection de personnes. Cette simplification permet de mieux contraindre le processus d’entraînement et d’améliorer la robustesse des modèles.
Optimisation de l’entraînement
Nous avons évalué trois tailles de modèles : nano (n), small (s) et medium (m), sur deux résolutions d’entrée : 224×224 et 54×42. Notre objectif était d’identifier le meilleur compromis entre performance et coût selon la taille du modèle et la résolution d’entrée. Cet équilibre est essentiel pour les contraintes de latence et ainsi permettre une détection temps réel sur système LiDAR. Nous avons automatisé le réglage des hyperparamètres. Pour cela, nous utilisons l’optimisation bayésienne avec YOLOv8 et Ray Tune. Contrairement à la recherche par grille, cette approche apprend des itérations précédentes afin d’explorer efficacement un espace de recherche continu et multidimensionnel. Enfin, la recherche d’hyperparamètres a été réalisée sur 15 itérations, suivie d’un entraînement avec une validation croisée à k=5. Les métriques de performance obtenues sont présentées ci-dessous.
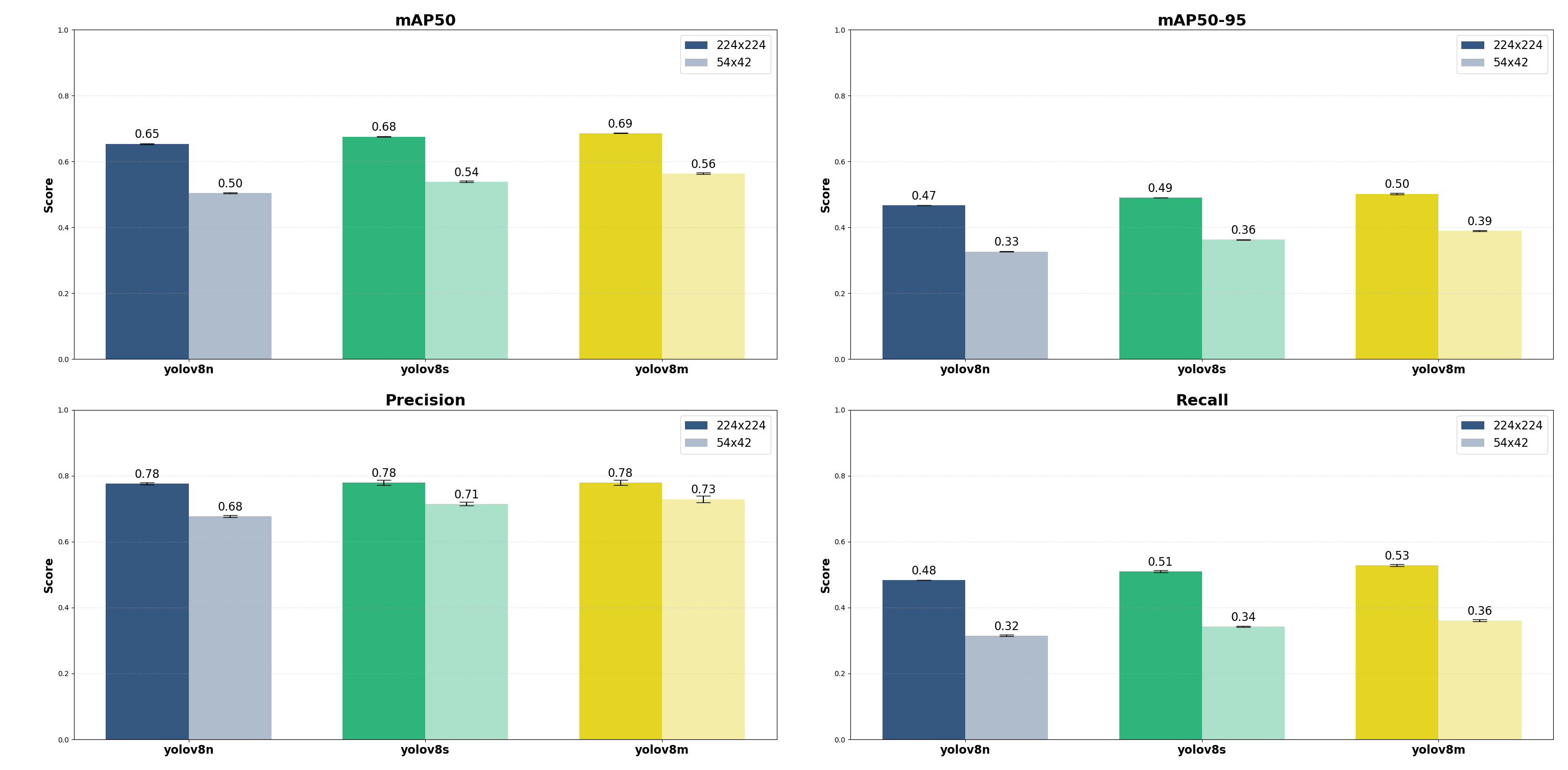
Interprétation et conclusion
Ces résultats nous permettent d’analyser deux facteurs clés pour la détection temps réel sur système LiDAR : la résolution d’entrée et la complexité du modèle.
La réduction de la résolution d’entrée de 224 px à 54 px est significative sur l’ensemble des métriques. Le rappel est le plus affecté. Il passe de 0,48–0,53 à 224 px à seulement 0,32–0,36 à 54 px. Donc à basse résolution, le modèle ne détecte pas 65 % des personnes. La dégradation de la précision est moins marquée que celle du rappel. La baisse est d’environ 10 % (de ~0,78 à ~0,68–0,73).
Concernant la complexité du modèle, les résultats montrent une progression logique des performances. Cependant les gains sont marginaux. Le modèle medium (YOLOv8m) obtient la meilleure performance globale, en particulier le rappel le plus élevé à 224 px (0,528). Ce qui est notable: YOLOv8n se révèle étonnamment compétitif à 224 px, avec un mAP50 de 0,65 contre 0,68 pour YOLOv8m. En comparaison, à 54 px, les modèles plus grands comme YOLOv8m ne parviennent pas à compenser la perte d’information spatiale. Cette observation est déterminante pour orienter les prochaines étapes d’optimisation. En pratique, YOLOv8n à 224 px surpasse nettement YOLOv8m à 54 px sur l’ensemble des métriques.
Pour la détection temps réel sur système LiDAR, le meilleur compromis est atteint avec YOLOv8n à une résolution de 224×224. Cette configuration égale les performances de modèles plus volumineux. De plus, elle est optimisée pour une exécution en temps réel sur un matériel contraint. Nous allons désormais optimiser le processus d’entraînement. L’objectif est d’améliorer le rappel tout en maintenant les performances globales, en prenant YOLOv8n à 224×224 comme référence. Ce travail est en cours.
Le prochain article portera sur l’optimisation matérielle afin d’obtenir une inférence optimisée pour la détection en temps réel sur un système LiDAR.