Estimation de profondeur monoculaire sur le Verdin i.MX95
Déploiement de l’estimation de profondeur monoculaire sur le Verdin i.MX95 pour l’IA embarquée : adaptation du modèle, quantification INT8 et une pile logicielle embarquée complète pour l’inférence de profondeur en temps réel à 30 FPS à partir d’une seule caméra RGB.
L’estimation de profondeur monoculaire consiste à reconstruire une carte de profondeur à partir d’une seule image capturée par une caméra RGB. Dans cet article, nous démontrons l’estimation de profondeur monoculaire sur le Verdin i.MX95. Le déploiement se base sur le modèle d’estimation de profondeur MiDaS sur le processeur NXP i.MX95, accélérant les performances de 7 FPS sur le CPU à 30 FPS sur le NPU Neutron pour atteindre une inférence en temps réel sur un module système Toradex Verdin iMX95. Nous couvrons l’intégralité des étapes d’ingénierie, de l’adaptation du modèle pour la compatibilité NPU à la quantification post-entraînement, la compilation NPU, l’intégration du pipeline GStreamer et l’assemblage de l’image Yocto.
Pourquoi l’Estimation de Profondeur Monoculaire Embarquée ?
La perception de la profondeur est fondamentale pour la robotique, la navigation autonome et l’inspection industrielle. Les approches traditionnelles reposent sur des caméras stéréo ou des LiDAR, qui ajoutent des coûts, une consommation d’énergie et une complexité de calibration. L’estimation de profondeur monoculaire élimine ces contraintes en inférant la profondeur à partir d’une seule caméra, un capteur déjà présent sur la plupart des plateformes embarquées.
Cependant, les modèles d’IA ayant cette capacité sont gourmands en calcul. Les exécuter sur un CPU à usage général à des cadences vidéo est impraticable sur la plupart des matériels embarqués. Le moteur Neutron du NXP i.MX95 change la donne. Il fournit le débit nécessaire à l’inférence du modèle tout en fonctionnant avec quelques watts de puissance.
Le module Toradex Verdin i.MX95, compatible matériellement avec l’écosystème Verdin et associé à la carte de développement Verdin, constitue une plateforme idéale pour ce projet. Il combine le NPU Neutron à 2 TOPS avec un cluster Cortex-A55 hautement économe en énergie.
Notre objectif était de démontrer qu’un pipeline complet d’estimation de profondeur monoculaire de bout en bout pouvait fonctionner entièrement sur ce module à 30 FPS.
Module Toradex Verdin i.MX95
Configuration complète : carte de développement Verdin, module système Verdin iMX95 et caméra CSI (OV5640)
Choisir le bon modèle : MiDaS v2.1 Small
Nous avons sélectionné le modèle MiDaS v2.1 256 de la famille Intel ISL MiDaS. Il utilise un encodeur EfficientNet-Lite3 et un décodeur RefineNet à quatre étapes avec un schéma de caractéristiques expansif (64 → 128 → 256 → 512 canaux). La résolution d’entrée est de 256×256 et la sortie est une carte de profondeur relative inverse à canal unique à la même résolution.
Bien qu’optimisé pour le déploiement embarqué, le modèle exige tout de même des ressources de calcul substantielles, n’atteignant que 7 FPS sur le CPU. Cela a motivé l’exploration des capacités d’accélération matérielle du NPU Neutron.
Adaptation du modèle pour le NPU Neutron
Le déploiement d’un modèle PyTorch sur un NPU dédié n’est pas une simple question de conversion de format. Certaines opérations qui fonctionnent bien sur les CPU et GPU peuvent ne pas être prises en charge par le matériel NPU.
L’adaptation que nous avons effectuée sur le modèle d’IA a consisté à remplacer toutes les interpolations bilinéaires par des interpolations au plus proche voisin. Laisser ces opérations inchangées forcerait 5 replis vers l’exécution CPU, impactant sévèrement la latence.
Nous avons comparé les cartes de profondeur float32 entre les modèles original (bilinéaire) et adapté (plus proche voisin) sur des images COCO. La validation effectuée sur un ensemble de validation de 1 000 images a donné une corrélation de Pearson minimale de 0,954, avec une moyenne de 0,997. Les cartes de profondeur sont structurellement quasi identiques. Les différences se concentrent aux limites des objets où l’interpolation bilinéaire produit des bords légèrement plus lisses, un compromis acceptable pour une exécution entièrement sur NPU.
Quantification et compilation NPU
Nous avons utilisé le SDK eIQ Neutron v3.0.0 pour l’intégralité du pipeline de conversion. Il s’agit d’un processus en trois étapes appliqué au modèle d’IA embarquée : profilage, quantification et compilation NPU.
Étape 1 : Export ONNX et conversion TFLite. Le modèle PyTorch adapté est exporté en ONNX (opset 17, forme statique). Le modèle ONNX est ensuite converti en TFLite float32 via le pont ONNX-TF, avec un format d’entrée NHWC.
Étape 2 : L’outil « neutron-profiler » exécute le modèle float32 sur un ensemble de données de calibration (images COCO avec normalisation ImageNet) pour collecter des histogrammes d’activation par tenseur. Ces histogrammes pilotent le neutron-quantizer, qui applique une quantification post-entraînement INT8 complète par tenseur.
Étape 3 : Compilation NPU. L’outil neutron-converter compile le modèle INT8 dans un fichier TFLite avec le microcode Neutron intégré. Cette étape effectue l’optimisation au niveau du graphe, l’extraction du sous-graphe Neutron, l’ordonnancement des tuiles, l’allocation TCM (Tightly Coupled Memory) et la génération de microcode.
Résultats de la compilation NPU
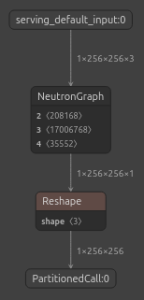
Le compilateur Neutron a atteint un taux de conversion des opérateurs de 99,45 % : 181 des 182 opérateurs s’exécutent nativement sur le NPU, regroupés dans un unique sous-graphe Neutron. Cela signifie que le NPU exécute l’intégralité du graphe d’inférence comme un seul appel noyau continu, minimisant la surcharge de transfert de données CPU–NPU.
MiDaS v2.1 Small compilé dans un unique sous-graphe Neutron monolithique
Résultats de la compilation NPU pour MiDaS v2.1 Small 256
Métrique
Valeur
Opérateurs du modèle d’IA
182
Opérateurs sur NPU
181
Opérateurs sur CPU (repli)
1
Taux de conversion
99,45 %
Sous-graphes Neutron
1
Latence estimée (@ 1 GHz)
11,58 ms
Le seul opérateur non converti est un simple reshape à la sortie du modèle, ajoutant quelques microsecondes de surcharge CPU par inférence.
Taille mémoire du modèle après le processus de compilation
Étape
Format
Taille
TFLite float32
float32
64 Mo
TFLite INT8 (quantifié)
INT8
17 Mo
TFLite + Neutron (compilé NPU)
INT8 + microcode
17 Mo
L’étape de quantification permet une réduction de taille de 3,8× par rapport au tflite float32. La compilation Neutron ne modifie pas significativement la taille du fichier car le microcode NPU et les tampons de poids sont comparables en volume aux données INT8 originales.
Construction du pipeline en temps réel
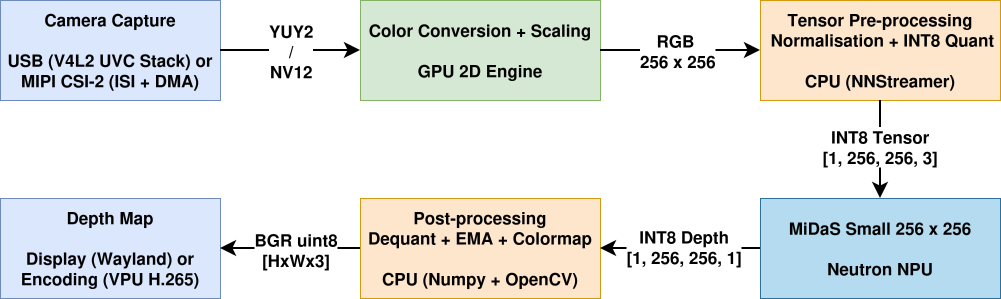
Un modèle d’IA embarquée fonctionnant sur le NPU de manière isolée n’est pas un produit fini. Nous avons construit un pipeline GStreamer complet pour gérer l’intégralité du chemin de données, de la capture caméra à la sortie visuelle.
Architecture du pipeline
Le système d’IA embarquée utilise une architecture à trois couches :
Prétraitement GStreamer/NNStreamer : capture caméra (USB ou CSI), conversion d’espace colorimétrique accélérée par matériel via le moteur GPU 2D, redimensionnement à 256×256 et normalisation ImageNet avec quantification INT8 via NNStreamer.
Thread d’inférence Python : les tenseurs INT8 prétraités sont extraits d’un appsink GStreamer vers un thread d’inférence dédié qui exécute l’interpréteur tflite avec le délégué Neutron.
Post-traitement et sortie : le tenseur de profondeur INT8 brut est dé-quantifié, lissé via EMA temporelle (α=0,4), filtré, normalisé avec écrêtage par percentile (valeur de 5, pour éliminer le scintillement dû aux valeurs aberrantes) et colorisé avec la palette inferno. Les sorties incluent un serveur HTTP MJPEG, un affichage Wayland et un enregistrement MP4 via l’encodeur matériel VPU.
Architecture de la chaîne de traitement
Éléments matériels utilisés
Étape
Matériel
Capture caméra
USB (pile V4L2 UVC) / MIPI CSI-2 (ISI + DMA)
Conversion couleur + mise à l’échelle
Moteur GPU 2D
Prétraitement des tenseurs
CPU (NNStreamer)
Inférence de profondeur
NPU Neutron
Post-traitement
CPU (NumPy + OpenCV)
Encodage vidéo (mode enregistrement)
VPU (H.265)
Pourquoi ne pas utiliser tensor_filter de NNStreamer ?
NNStreamer fournit un élément « tensor_filter » conçu exactement pour ce cas d’usage, exécutant l’inférence TFLite à l’intérieur d’un pipeline GStreamer. Nous avons initialement mis en œuvre cette approche, mais avons rencontré un problème critique : « tensor_filter » charge correctement le délégué Neutron mais retourne des tenseurs de sortie incorrects (cartes de profondeur presque sans caractéristiques). La même entrée prétraitée, lorsqu’elle est fournie à Python « tflite_runtime » avec le même délégué, produit des cartes de profondeur correctes. Bien que moins élégante d’un point de vue de la pureté GStreamer, cette approche fournit des résultats corrects et, grâce au découplage par threads, n’introduit pas de goulot d’étranglement en termes de performances.
Intégration Yocto : du modèle à l’image flashable
L’ensemble de la pile logicielle a été initialement assemblé dans une image Linux flashable à l’aide du projet Yocto (version Walnascar) avec l’orchestrateur de build kas, en utilisant une méta-couche personnalisée pour encapsuler nos configurations spécifiques au projet.
Pour obtenir TFLite 2.19 et le délégué Neutron, nous avons uniquement inclus « meta-imx-ml » tout en excluant « meta-imx-bsp » pour éviter les conflits avec la propre couche BSP de Toradex. La couche « meta-imx-bsp » est la couche BSP de référence de NXP. Lorsqu’elle est active, elle définit inconditionnellement des affectations globales qui redirigent « virtual/kernel » vers le fork du noyau NXP et « virtual/bootloader » vers le fork U-Boot de NXP. À l’inverse, les couches de Toradex (« meta-toradex-nxp », « meta-toradex-bsp-common ») fournissent leurs propres forks qui contiennent des correctifs spécifiques au Verdin, les arbres de périphériques des cartes et les séquences d’initialisation SOM. Enfin, « meta-imx-ml » ne contient que des recettes de bibliothèques ML comme TFLite 2.19 et les délégués Neutron / Ethos-U / VX, sans aucune configuration de noyau, de chargeur de démarrage ou de machine. Étant donné que ses seules dépendances de couche sont « core » et « freescale-layer », elle peut être ajoutée au-dessus de n’importe quel BSP sans conflit.
Ce mélange a nécessité des solutions de contournement ciblées via des fichiers bbappend, le patching des recettes ATF, l’épinglage des révisions U-Boot et l’ajustement des vérifications QA pour OpenCV. La recette d’image assemble une pile complète : GStreamer (base + good + bad + ugly), NNStreamer (core + TFLite + Python3), runtimes ML (TFLite 2.19 + délégué Neutron), OpenCV, paquets Python, compositeur Weston et les scripts et modèles de l’application d’estimation de profondeur.
Résultats et performances
Partant d’un ~7 FPS contraint sur le CPU, la solution finale déployée sur le module système Toradex Verdin iMX95 avec la carte de développement Verdin atteint ~30 FPS d’estimation de profondeur de bout en bout sur le NPU Neutron, en utilisant des caméras USB ou CSI (OV5640).
Le FPS de bout en bout est mesuré en horodatant chaque image produite tout au long du pipeline complet : capture caméra, conversion couleur et mise à l’échelle accélérées par GPU, prétraitement des tenseurs, inférence du modèle, post-traitement (dé-quantification, lissage EMA, palette de couleurs) et rendu d’affichage Wayland. La ligne de base CPU exécute le modèle MiDaS quantifié INT8 via tensor_filter de NNStreamer avec le délégué XNNPACK, atteignant ~7 FPS. La configuration NPU exécute le même modèle compilé pour le NPU Neutron, exécutant 99,45 % des opérations sur l’accélérateur, atteignant ~30 FPS, soit une amélioration de +330 %.
La latence par étape est profilée à l’aide de l’instrumentation time.perf_counter(). Deux chemins de code existent selon le backend. Avec le NPU, l’inférence contourne NNStreamer et est exécutée en Python via tflite_runtime avec le délégué Neutron. Un thread dédié mesure indépendamment l’extraction du tampon, invoke(), le post-traitement et l’affichage. Avec le CPU, l’inférence s’exécute nativement en C++ à l’intérieur de tensor_filter de NNStreamer. Puisqu’elle se termine avant le déclenchement du callback Python, le temps d’inférence est estimé comme capture_interval − callback_total, où capture_interval est le temps d’horloge entre les émissions consécutives du sink de tenseurs et callback_total est le temps de post-traitement Python mesuré. Toutes les métriques sont moyennées sur des fenêtres de 100 images pour lisser les fluctuations d’ordonnancement.
Mesures de latence entre le pipeline NPU et le pipeline CPU
Étapes mesurées
Pipeline NPU (ms)
Pipeline CPU (ms)
Prétraitement
0,4
0,3
Inférence
~10,9
~110
Post-traitement
8,7
7,3
Affichage
~13,1
~12,2
FPS de bout en bout
~30 FPS
~7 FPS
Démonstration vidéo de l’estimation de profondeur monoculaire fonctionnant sur le Verdin iMX95
Principaux éléments d’ingénierie à retenir
Le déploiement d’un modèle d’estimation de profondeur sur un NPU n’est pas du plug-and-play. Plusieurs leçons ont émergé de ce projet :
La compatibilité des opérateurs pilote l’adaptation du modèle. Une seule opération non prise en charge (interpolation bilinéaire) aurait forcé des replis significatifs vers le CPU. La validation systématique de la substitution par rapport aux seuils de qualité était essentielle.
La normalisation de calibration doit correspondre exactement à la normalisation d’inférence. Cela semble évident a posteriori, mais une inadéquation était l’un des trois bogues qui ont produit des cartes de profondeur incorrectes durant le développement.
NNStreamer avec le délégué Neutron produisait des résultats incorrects, nécessitant un contournement de l’inférence basé sur Python. Un débogage fin a été nécessaire.
Un support NPU avec un graphe unique est l’objectif. Atteindre 99,45 % de conversion des opérateurs avec un seul sous-graphe Neutron élimine la surcharge de transfert CPU–NPU pendant l’inférence. Cela a nécessité à la fois une adaptation du modèle et un contrôle minutieux du format.
La pile complète est importante : la précision du modèle ne fait pas sens sans le pipeline environnant, les pilotes de caméra, le prétraitement accéléré par matériel, la gestion des tampons et un système de build qui assemble de manière fiable toutes les dépendances.
Conclusion
Nous avons démontré que l’estimation de profondeur monoculaire en temps réel est réalisable sur le Toradex Verdin iMX95 en utilisant le modèle MiDaS v2.1 Small. L’estimation de profondeur monoculaire sur du matériel basse consommation est applicable à des applications où les LiDAR et configurations stéréo sont trop coûteux, lourds ou fragiles, tels que la navigation AMR/entrepôt, l’évitement d’obstacles agricoles dans la poussière/la lumière solaire et l’inspection industrielle pour séparer les défauts de l’arrière-plan. La proposition de valeur est de remplacer les capteurs de profondeur dédiés par une pile logicielle sur une caméra standard et un SoC embarqué basse consommation.
Le chemin d’un modèle PyTorch à une application embarquée à 30 FPS a nécessité une ingénierie à chaque couche : adaptation du modèle pour la compatibilité des opérateurs NPU, quantification post-entraînement INT8 via le SDK eIQ Neutron, conception du pipeline GStreamer avec prétraitement accéléré par matériel et un système de build basé sur Yocto qui intègre les couches BSP Toradex avec les runtimes ML NXP.
Le résultat est une pile d’IA embarquée complète et reproductible, du code source à l’image flashable, qui transforme un flux de caméra unique en une carte de profondeur en temps réel sur une plateforme embarquée économe en énergie. Ce travail a été démontré à Embedded World 2026 et fonctionne sur un module Toradex Verdin i.MX95.
Démonstrations en direct au stand 4-642 (Hall 4) pour présenter des pipelines de vision par ordinateur avec l’IA en temps réel, optimisés pour les accélérateurs matériels embarqués et construits sur l’écosystème open source de l’IA. Nuremberg, Allemagne, le 6 mars 2026 – Savoir-faire Linux, une société leader dans le domaine de l’ingénierie logicielle open […]
Entraînement de YOLO pour la Détection Temps Réel sur Système LiDAR Il s’agit du deuxième volet d’une série en trois parties consacrée à la détection temps réel sur système LiDAR. Retrouvez ici l’article 1 sur la génération de jeux de données synthétiques de profondeur et NIR. Actuellement, de nouveaux LiDAR embarqués à basse résolution, tels […]
Permettre la Détection Temps Réel grâce à la Génération de Données LiDAR Synthétiques Cette série d’articles couvrira les éléments essentiels au déploiement d’un système de détection en temps réel avec un module dToF 3D LiDAR. Ce premier article est consacré à la génération de données LiDAR synthétiques. Génération de données LiDAR synthétiques pour la détection […]