Optimizing YOLO Training for Real-Time Detection on a LiDAR system
This is the second of a three-part series on real-time YOLO detection on a LiDAR system for Edge AI. Find Article 1 on generating synthetic depth and NIR datasets here.
Currently, new low-resolution embedded LiDAR such as the VL53L9CX, are emerging as a highly suitable option for robotic systems. This 54×42 pixel array simultaneously provides low-power depth, infrared, and active illumination data. Specifically, integrating an optimized YOLO model can transform these signals into real-time perception.
We start this article by quickly introducing the YOLO convolutional neural network family. Then, we conduct an exploratory study evaluating YOLO’s accuracy across multiple datasets to assess the impact of different image modalities. We conducted training experiments using relative depth, absolute depth, near-infrared (NIR), and multimodal (depth + NIR) inputs. For details regarding the generation of these datasets, we refer the reader to article 1 of this series. Finally, we discuss YOLO hyperparameter optimization to achieve the best possible performance given the characteristics of the input data.
Introduction to YOLO and YOLOv8: Real-Time Computer Vision
In the field of computer vision, YOLO (You Only Look Once) has fundamentally transformed how machines perceive the visual world. Specifically, YOLO replaces multi-stage pipelines with a single forward pass. It performs region proposal and classification simultaneously. As a result, this one-shot architecture enables extremely fast inference. It makes real-time object detection feasible even on video streams.
The Evolution Toward YOLOv8
YOLOv8, released by Ultralytics in 2023, remains the state of the art for balancing accuracy and efficiency. However, we utilize YOLOv8 over newer versions like YOLO11 due to its superior support on industrial hardware, specifically NPU platforms.
YOLOv8 introduces several key architectural improvements:
- Anchor-Free Architecture: unlike earlier YOLO versions, YOLOv8 directly predicts object centers without relying on predefined anchor boxes. This significantly improves detection accuracy, especially for human figures with diverse postures and scales.
- C2f Backbone: the Cross-Stage Partial Bottleneck (C2f) module enhances gradient flow while reducing model complexity. Therefore, it results in lighter models with improved performance.
- Native Task Versatility: beyond bounding-box detection, YOLOv8 natively supports instance segmentation and pose estimation. Thus, it offers a clear path toward more advanced perception and behavioral analysis tasks.
In short, YOLOv8 achieves superior Pareto efficiency in terms of latency-mAP when considering datasets and execution on embedded platforms. This makes it perfectly suited for real-time detection on a LiDAR system for Edge AI.
Training Strategies for Real-time Detection on a LiDAR System
We compared two strategies to determine the best approach for high-performance and robust embedded deployment. Strategy 1 employs a Mixture of Experts (MoE). Alternatively, strategy 2 uses multimodal single-model training.
- Strategy 1: Mixture of Experts (MoE)
A Mixture of Experts (MoE) approach uses two parallel YOLOv8 models, respectively specialized in Depth and NIR data. From a methodological standpoint, this strategy is more straightforward, as each model is optimized for a single modality.
Nonetheless, it raises several critical questions. First, does each modality provide enough discriminative information at ultra-low resolution to perform independently? Second, can low-power embedded architectures support concurrent inference pipelines within strict latency, power, and memory limits?
- Strategy 2: Multimodal Single-Model Training
The second approach consists of training a single YOLOv8 model on multimodal input images. While conventional RGB images contain three channels, our inputs are composed of two channels only: depth and near-infrared (NIR). Executing this strategy involves fusing modalities into a new dataset and adapting the training pipeline for custom input representations.
The primary challenge is whether the network can generalize from this unconventional modality. However, a single-model pipeline significantly reduces computational overhead and simplifies inference on resource-constrained embedded systems.
Experimental Results Overview
We present the results of the following training with YOLOv8 on three datasets:
- NIR dataset, generated through inference using the Pix2Next model.
- Depth dataset, produced via inference from the ZoeDepth model.
- Multimodal dataset, where each image simultaneously includes depth and NIR channels.
In this context, several variants were evaluated across these strategies. We evaluated YOLOv8 vs. YOLO11 across from scratch training and RGB-pretrained weights (transfer learning). In addition, we used nano (n), small (s), and medium (m) topologies.
The following table summarizes the tested models and highlights their benchmark performance on 640×640 input images. While mAP val 50–95 measures detection quality and consistency, parameters and FLOPs estimate inference cost. However, these metrics require contextualization for NPU deployment and hardware-specific optimizations.
| Model | Size (pixels) | mAP val 50–95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | Parameters (M) | FLOPs (B) |
|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLO11n | 640 | 39.5 | 56.1 ± 0.8 | 1.5 ± 0.0 | 2.6 | 6.5 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLO11s | 640 | 47.0 | 90.0 ± 1.2 | 2.5 ± 0.0 | 9.4 | 21.5 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLO11m | 640 | 51.5 | 183.2 ± 2.0 | 4.7 ± 0.1 | 20.1 | 68.0 |
Optimizing Training: Selecting and Interpreting the Right Metrics
To start, a comprehensive evaluation of YOLOv8 performance requires a multi-metric approach rather than relying on a single indicator. The objective is to optimize the trade-off between localization accuracy and detection sensitivity. This will enable us to effectively adjust our training for real-time YOLO detection on a LiDAR system.
Firstly, the primary detection metrics used are precision and recall. Precision and recall are the core metrics for performance analysis.
- Precision quantifies model reliability by measuring the ratio of correct detections to total predictions (minimizing false positives).
- Recall measures sensitivity by calculating the proportion of actual objects successfully detected. Accordingly, low recall reflects a high number of false negatives, where the model fails to detect existing objects.
Furthermore, the F1 score is the harmonic mean of precision and recall. It is particularly useful during training, as it summarizes overall performance into a single value. If the F1 score plateaus while precision continues to improve, it often indicates a drop in recall. This insight is valuable for adjusting the confidence threshold in order to rebalance precision and recall.
Secondly, a metric specific to object detection is mAP (mean Average Precision), which is the standard benchmark for comparing detection models. It is computed as the area under the precision–recall curve.
- MAPval 50 measures the average precision with an Intersection over Union (IoU) threshold of 0.5. It primarily reflects the model’s ability to detect objects at a coarse level.
- MAPval 50-95 is a stringent metric averaging mAP across IoU thresholds from 0.5 to 0.95, high scores reflect superior bounding box alignment with ground truth.
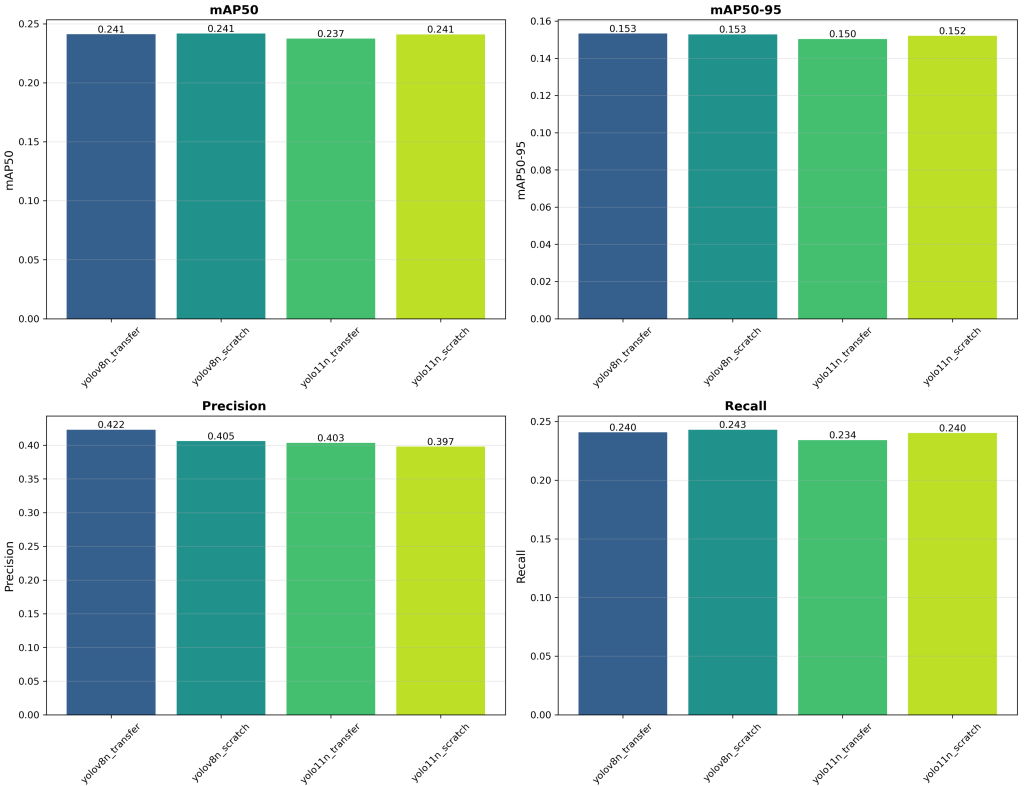
YOLO on the NIR Dataset
Initial training experiments were conducted on a dataset comprising 10 classes: [‘person’, ‘bench’, ‘backpack’, ‘bottle’, ‘cup’, ‘chair’, ‘tv’, ‘laptop’, ‘cell phone’, ‘book’].
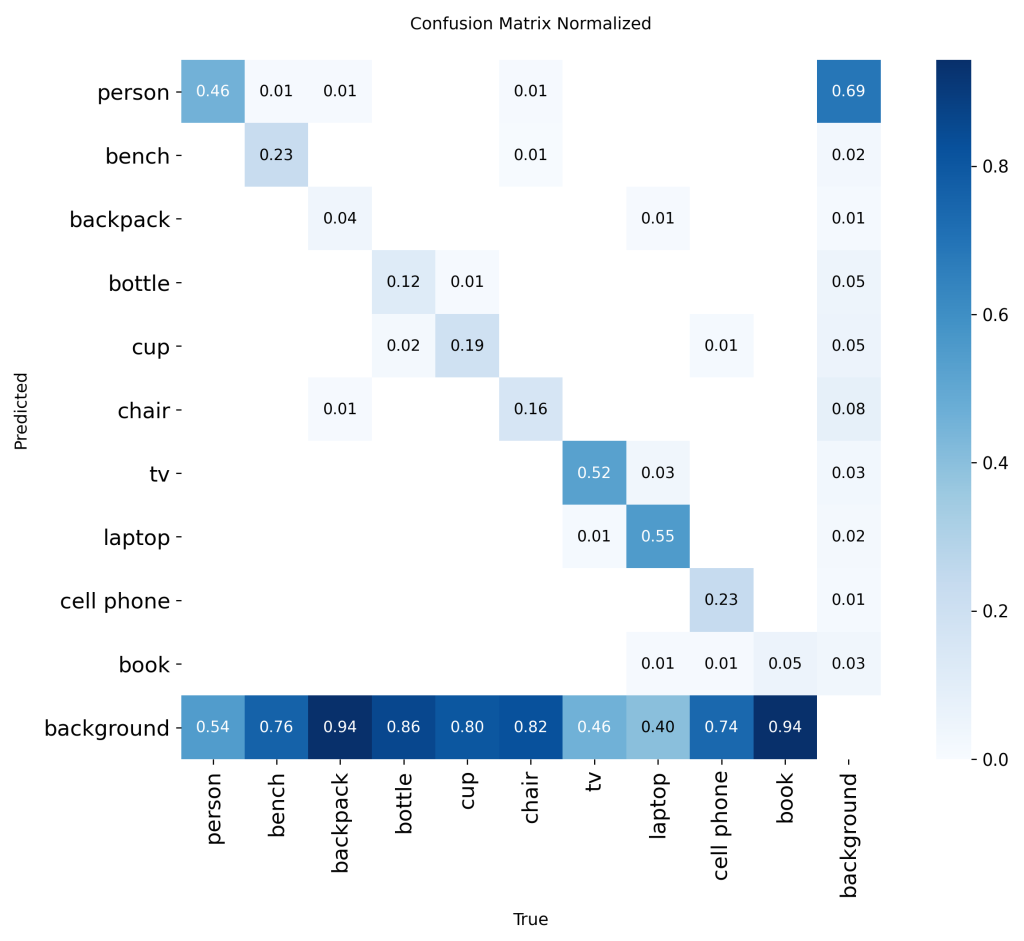
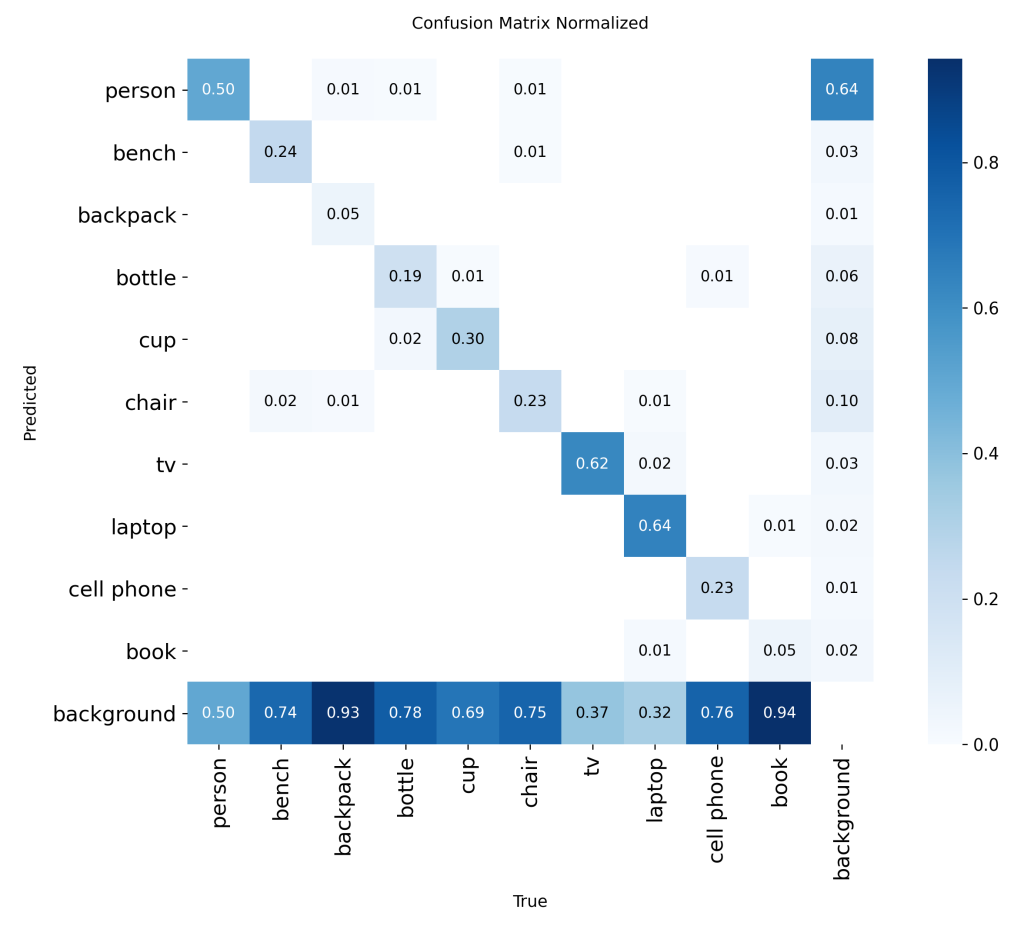
Unfortunately, detection was hindered by the NIR modality and the ultra-low 54×42 input resolution. As a result, both MAPval 50-95 and MAPval 50 exhibit poor performance on this modality. In addition, precision and recall are also very low. It indicates a high rate of false positives and false negatives. Further analysis using the normalized confusion matrix provides deeper insight into the model’s class-wise detection capabilities. It highlights which classes are most affected and where misclassifications occur. The normalized confusion matrix presented corresponds to a YOLOv8s model trained from scratch, serving as a baseline for subsequent improvements.
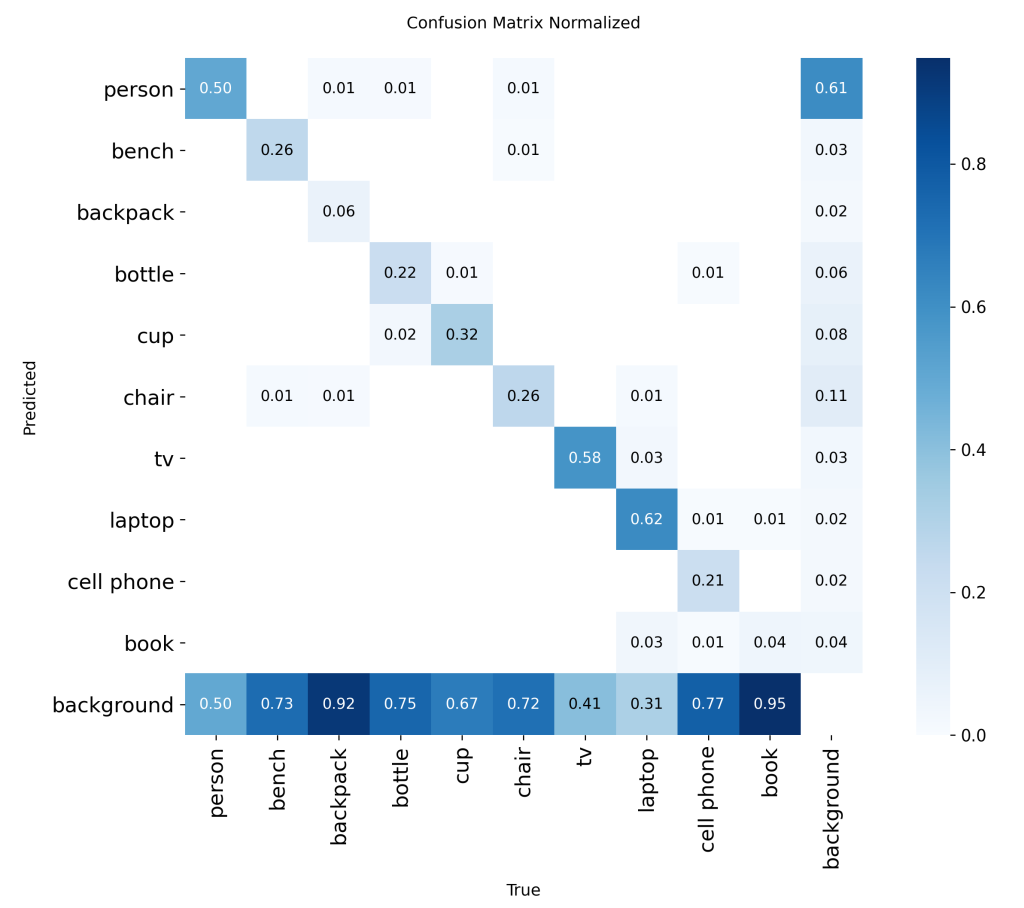
YOLOv8 on the Depth Dataset
Although the NIR modality yields better detection results, the overall performance of the models remains insufficient. The MAPval 50-95 is not exceeding 0.25. The confusion matrix displayed above corresponds to a YOLOv8s model trained from scratch on the depth dataset. These preliminary results highlight that an MoE approach may not be optimized for real-time YOLO detection on a LiDAR system for Edge AI.
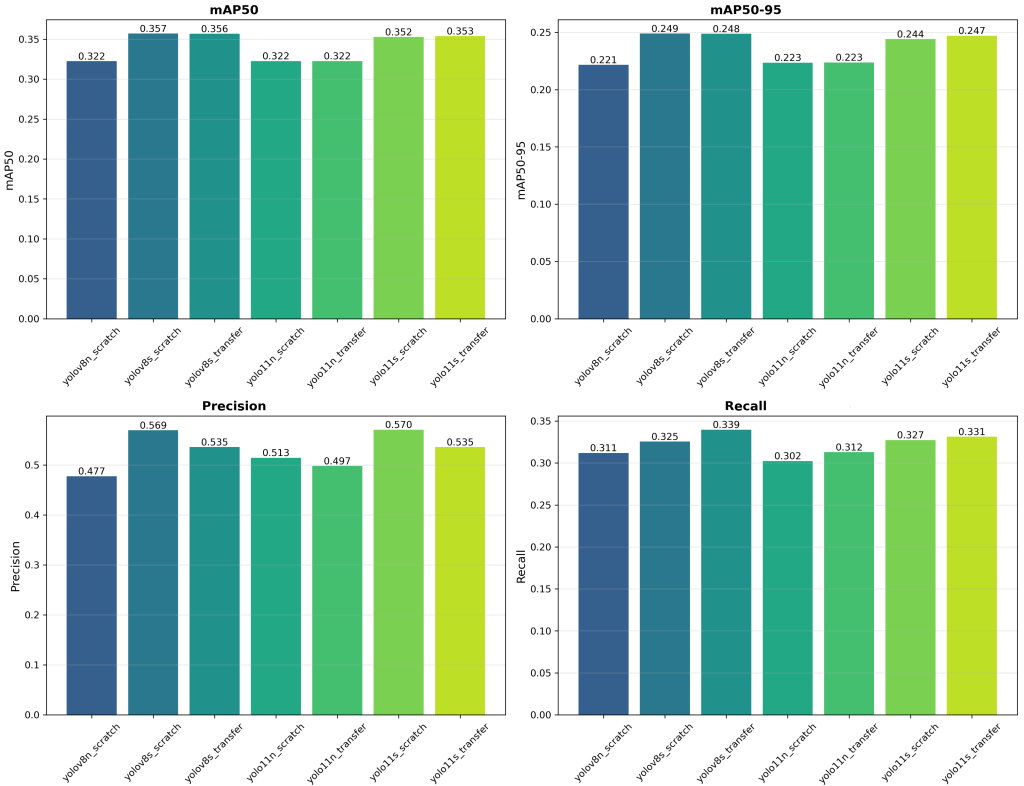
YOLOv8 on a Multimodal Dataset
Following these initial training results, we decided to discontinue transfer learning. Instead, we focused on training the models from scratch. With marginal performance differences, we focused on specializing the model on depth and NIR modalities. Due to poor single-modality performance, we implemented a two-channel Depth-NIR fusion for the YOLOv8 input. This multimodal representation enriches input data with complementary features, enhancing detection under constrained sensing conditions.
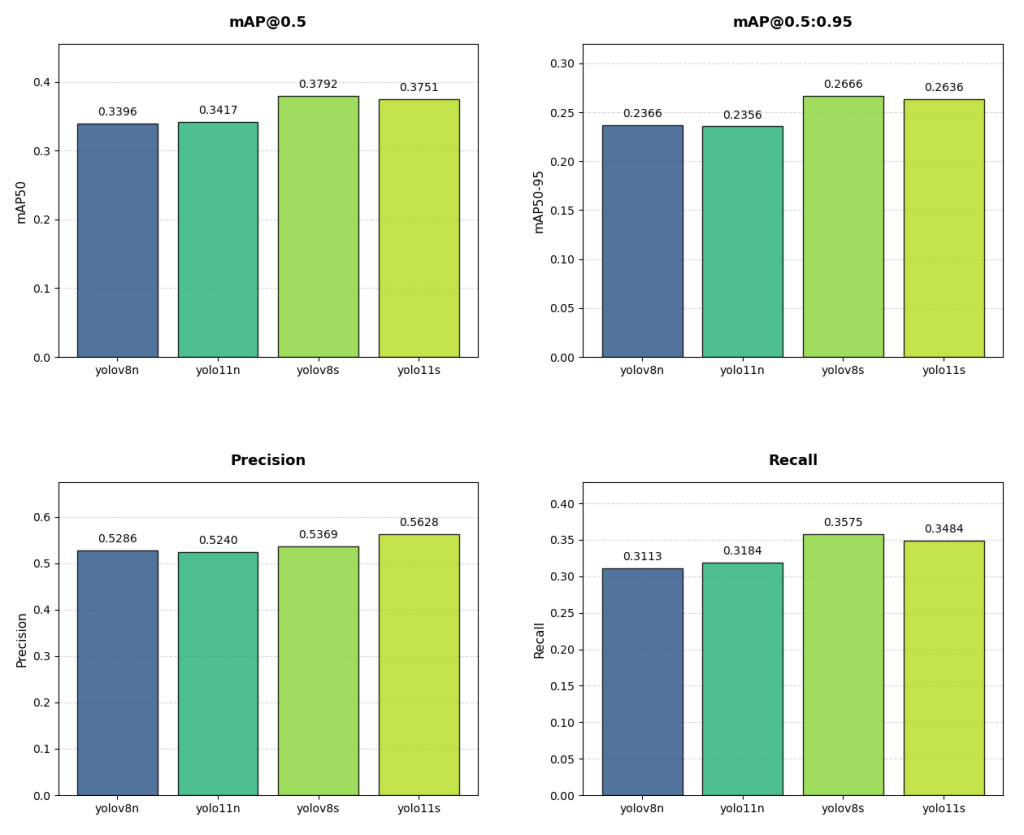 |  |
Despite training on two modalities to enrich the extracted features, the results are not yet satisfactory. Currently, the performance difference between YOLOv8 and YOLOv11 is not significant. Consequently, we prioritized the model that delivers the best performance on the target hardware, namely YOLOv8. Since YOLOv11 does not provide any significant accuracy gains, the associated loss in hardware efficiency is not justified. For real-time detection on a LiDAR system for Edge AI, hardware constraints are crucial and must be taken into account early in the process.
In addition, certain classes, such as books and backpacks, are barely detected. Low resolution and modality constraints prevent reliable object characterization. As a result, we decided to narrow the scope of the task and focus exclusively on person detection. This simplification allows us to better constrain the training process and improve the robustness of the models.
Training Optimization
We therefore evaluated three model scales, nano (n), small (s), and medium (m), across two input resolutions: 224×224 and 54×42. Our goal was to seek the best trade-off between performance and cost across model sizes and input resolutions. Moreover, we automated hyperparameter tuning via Bayesian optimization using YOLOv8’s integration with Ray Tune. Unlike grid search, this approach learns from previous iterations to efficiently explore a continuous and multidimensional search space. Finally, the hyperparameter search was performed over 15 iterations, followed by training using 3-fold cross-validation. The resulting performance metrics are presented below.
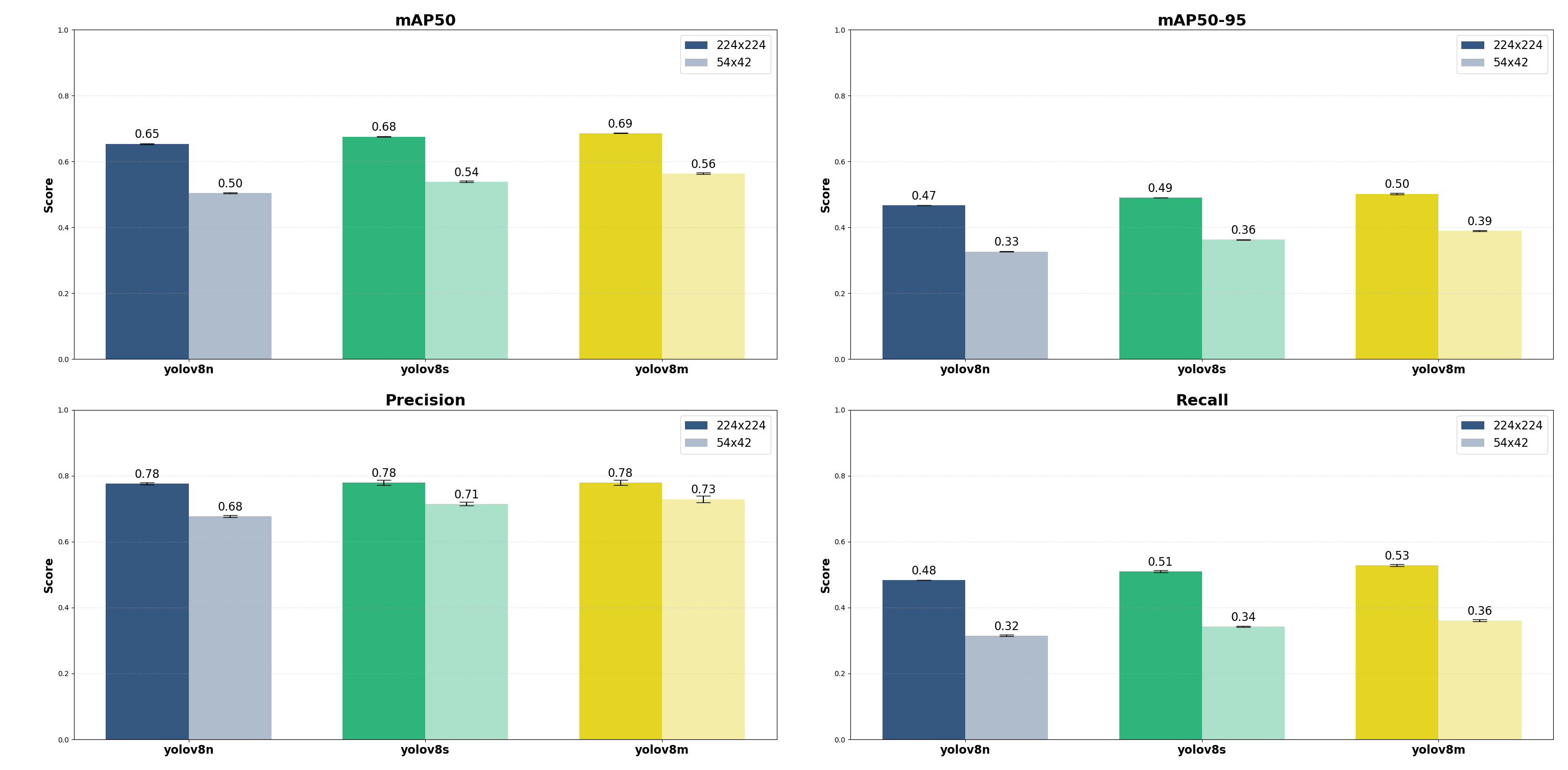
Interpretation and Conclusion
In conclusion, these results allow us to analyze two key factors for real-time detection on a LiDAR system: input resolution and model complexity.
The impact of reducing the input resolution from 224×224 to 54×42 is significant across all metrics. Recall is the most affected, dropping from 0.48–0.53 at 224 px to only 0.32–0.36 at 54 px. This indicates that, at low resolution, the model fails to detect approximately 65% of the people present in the scene. Precision degradation is less severe than recall, with an average decrease of about 10% (from ~0.78 down to ~0.68–0.73). Blurred silhouettes at low resolution cause more false positives as objects blend into the background.
Regarding model complexity, i.e., nano vs. small vs. medium, the results show a logical performance progression, but with marginal gains. The medium model (YOLOv8m) achieves the best overall performance, in particular the highest recall at 224 px (0.528). Above all, YOLOv8n is surprisingly competitive at 224 px, achieving a 0.65 mAP50 versus 0.68 for the medium model. Indeed, at 54px, larger models like YOLOv8m fail to offset spatial information loss. This observation is critical for guiding the next optimization steps. In practice, YOLOv8n at 224 px significantly outperforms YOLOv8m at 54 px across all metrics.
Overall, for real-time detection on a LiDAR system for Edge AI, the best trade-off is achieved with YOLOv8n at a resolution of 224×224. This configuration matches the performance of larger models but is optimized for real-time execution on limited hardware. We will now optimize the training process to improve recall while maintaining overall performance, referencing YOLOv8n at 224×224. This is a work in progress.
The next article will focus on hardware implementation and optimization of NPU usage to achieve optimized inference for real-time detection on a LiDAR system.