[L’introduction est en français, le reste du texte en anglais]
TL;DR
- Les systèmes audio utilisent souvent des périphériques asynchrones, qui ont besoin d’être synchronisés avec du ré-échantillonnage.
- Nos mesures montrent que la charge CPU du ré-échantillonnage peut atteindre presque 30% d’un cœur sur un SoC i.MX8M Nano.
- Utiliser l’endpoint de feedback de l’USB gadget UAC2 est une optimisation possible.
alsaloop implémente l’utilisation du feedback, Pipewire aussi depuis une version récente.
Un serveur de son est un logiciel permettant à plusieurs applications d’accéder aux périphériques audio d’un système. Il effectue aussi diverses conversions, car les périphériques audio peuvent utiliser des formats et fréquences d’échantillonnage différentes. Pour cela du ré-échantillonnage est souvent effectué.
Au sein de l’écosystème Linux, les serveurs de son les plus utilisés à l’heure actuelle sont JACK et Pulseaudio. Pipewire est un projet plus récent qui veut offrir une alternative à ces deux solutions. Il est compatible avec les APIs de JACK et Pulseaudio et montre des performances prometteuses. Dans ce contexte, Pipewire gagne de plus en plus en popularité et est maintenant disponible sur plusieurs distributions.
Cet article se concentrera sur la charge CPU causée par le ré-échantillonnage audio sur plateforme embarquée. Nous utiliserons Pipewire, ainsi que plusieurs périphériques audio asynchrones pour simuler un cas d’usage complexe. Nous nous attendons à observer un impact non négligeable sur la charge CPU qui pourrait être réduit.
Pour plus d’informations concernant Pipewire, vous pouvez consultez les deux articles précédents sur le sujet:
Experimental setup
Hardware and Linux distribution
- An AUD-EXP-42448 Audio Card integrating a cs42448 chip: 6 input channels, 8 output channels. We will refer to it as the cs42448 in this article.
- A USB UAC2 gadget, receiving and transmitting audio from a host: 8 input channels, 8 output channels.
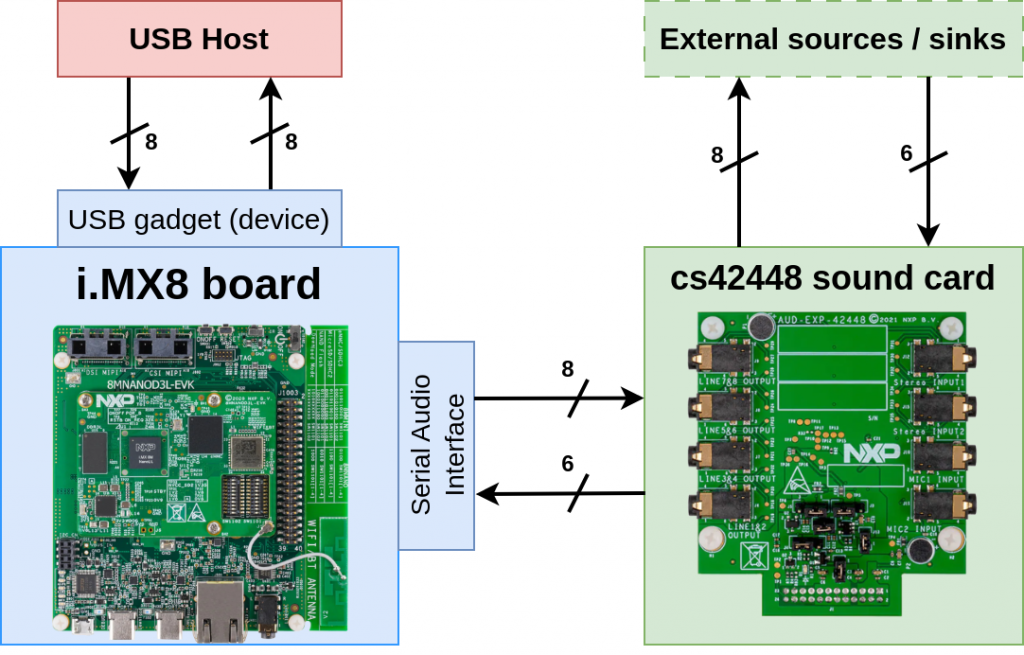
Figure 1: measurement environment
The Linux distribution used on the i.MX8 is built using the Yocto Project, Kirkstone version. It runs a Linux mainline kernel with RT patch, version 6.1.26-rt8, and a Pipewire daemon version 0.3.71.
Pipewire configuration
We want Pipewire to mix audio from sources with different sample rates. This requires all sources to be synchronized. The rate of processing graph will also change to trigger or not the resampling.
About the Pipewire configuration, we can note that:
- Unless specified otherwise, the processing graph rate is 48 kHz.
- Source and sink of a same device are configured with the same
clock.name property. This notifies Pipewire that the underlying hardware of each pair of nodes rely on the same clock. Pipewire can then skip unnecessary resampling, helping us show the impact of resampling. - The resampler uses the default value of 4 for
resample.quality. A higher value means better resampling and audio with less aliasing, but a higher CPU load. According to Pipewire documentation, 4 is « good compromise between quality and performance ».
Setups
We have tested 4 different setups:
- Crossed audio (44.1 kHz – 48 kHz): sources of USB are routed to sinks of cs42448, and vice versa. Sample rates are 44.1 kHz for the USB, 48 kHz for the cs42448, meaning Pipewire will have to perform resampling.
- Crossed audio (48 kHz – 48 kHz): same as above, but USB also has a sample rate of 48 kHz. Resampling occurs as devices have different reference clocks. For the cs42448, it comes from its own audio PLL. For the USB gadget, its audio is synchronized with the USB host through the isochronous transfer.
- CS42448 loopback (48 kHz): simple loopback for the cs42448, from its source to its sink. No resampling will be done as:
- Sources and sinks rely on the same clock.
- The processing graph and the device have the same rate.
- CS42448 loopback (44.1 kz): same as previous setup, but the processing graph rate is set to 44.1 kHz. It forces resampling between device and processing graph.
To do the measurements, we use 2 well known tools:
htop: to get a global idea of the Pipewire process CPU load.perf: to get more precise measures about the CPU load of the resampling.- We measured on the complete system, illustrating the impact in a potential use case. The command used was:
perf record -ag -- sleep 30
Measurements of the resampling CPU load
Table 1 presents the results for the 5 setups previously described. It shows the measured CPU load with htop, as well as the CPU load of the resampling deduced with the perf measurements. All measurements have been done at least twice to assure consistent results.
A few remarks regarding the configuration and the results:
- The i.MX8M Nano has a 4 CPU cores, the theoretical maximum CPU load is 400%.
- Measurements with
htop are not precise. The general idea of the CPU load is enough to show the impact of the resampling. - Each measurement was done for at least 20 seconds. Peaks outside of the intervals might happen for short periods of time. As we measure the whole system, we assumed they are outliers.
- Pipewire performs resampling with
libspa-audioconvert.so, calling the functions below. <type> is the implementation used and may change depending on the platform.do_resample_full_<type>()do_resample_inter_<type>()do_resample_copy_c()
- For our measurements,
<type> was neon. - The CPU load of the resampling was computed from
perf and htop measurements. perf shows the percentage of samples spent in a function. Samples only represent the active load of the CPU. Therefore, the equation to compute the resampling CPU load is (resampling-perf-percentage / pipewire-perf-percentage) * pipewire-CPU-percentage.
Table 1 : CPU load measurement results| Setup | CPU load with htop | perf samples related to resampling | perf samples related to pipewire | Resampling CPU load |
Crossed audio
(44.1 kHz – 48 kHz) | 50% ~ 55% | 33.37% | 62.91% | 26.52% ~ 29.17% |
Crossed audio
(48 kHz – 48 kHz) | 24% ~ 30% | 14.38% | 31.65% | 7.60% ~ 9.50% |
CS42448 loopback
(48 kHz) | 9% ~ 12% | No sample | 24.26% | 0% |
CS42448 loopback
(44.1 kHz) | 29% ~ 31% | 25.73% | 50.43% | 14.80% ~ 15.82% |
We observe that Pipewire avoids useless resampling. With CS42448 loopback (48 kHz), all sample rates and clocks match, so no resampling is done. In CS42448 loopback (44.1 kHz) however cs42448 sample rate don’t match with the graph, resampling is done.
Crossed audio (48 kHz – 48 kHz) only has its device clocks not matching. Compared to Crossed audio (44.1 kHz – 48 kHz), Pipewire performs less resampling. Configuration is then an important step to reduce resampling and CPU load.
However the impact is still significant, reaching almost 30% of CPU load in some cases. This can be a real problem with complex audio embedded applications.
An external ASRC (Asynchronous Sample Rate Converter) could for example perform this task instead of the CPU, but would increase hardware cost.
Adapting audio speed with USB feedback
USB feedback principle
With recent versions of Linux, the USB UAC2 gadget now supports the feedback endpoint. It allows USB devices to signal the host to adapt the amount of sample sent over time. The USB device then assumes the captured audio rate match whatever is the reference. Resampling is then not needed anymore even if hardware clocks are different.
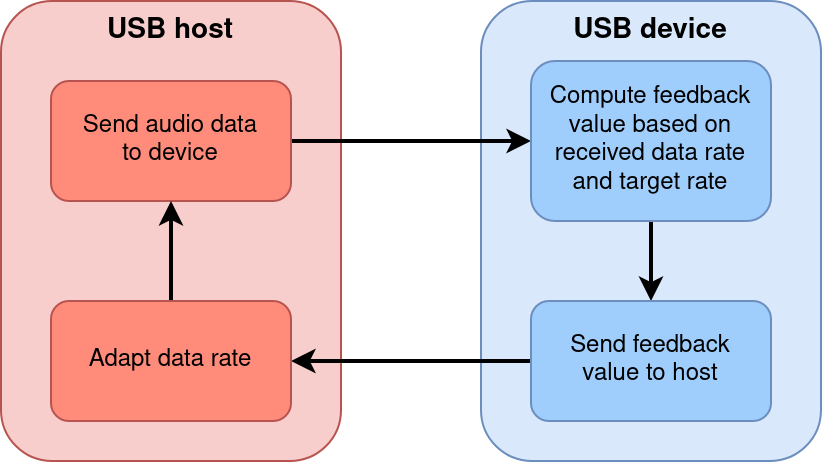
Figure 2: USB feedback principle
On the device side, alsaloop already implements the use of the feedback endpoint. With a USB UAC2 gadget as capture in async mode, alsaloop skips resampling. This can be verified with perf, searching for calls of libsamplerate.so. If we connect the USB source to the cs42448 sink with alsaloop, we observe a reduction of CPU load. htop shows 38% CPU load without feedback, 10% with. Once again, not doing resampling saves a lot of CPU resources.
Pipewire implementation
Since version 0.3.72, Pipewire supports the feedback endpoint. We updated the stress test setup to use it. To achieve this, it is necessary to adapt the configuration. The sample rate of the USB device must match the sample rate of the cs42448. The USB gadget configuration must also set the capture sync type to « async ».
Table 2 shows results of the Crossed audio (48 kHz – 48 kHz) setup with the USB gadget feedback support. The cs42448 and USB audio gadget have the same sample rates, so USB feedback can be used. Results without feedback are copied from table 1 for comparison.
Table 2 : Resampling CPU load for Crossed audio (48 kHz – 48 kHz) setup with feedback support| Use feedback endpoint | CPU load of pipewire with htop | perf samples related to resampling | perf samples related to pipewire | Resampling CPU load |
| No (USB gadget in adaptive mode) | 24% ~ 30% | 14.38% | 31.65% | 7.60% ~ 9.50% |
| Yes (USB gadget in async mode) | 20% ~ 23% | No sample | 35.25% | 0% |
With adapted sample rates, Pipewire does not resample streams anymore. The CPU load reduction with the feedback is between 7% and 10%. It is interesting for performance and only requires some configuration.
Conclusion
Real use cases can be more complex or ask for heavier processing than the measurement setups. It is common to have other software on top of the audio pipeline, for example doing noise cancellation. In this case, 20% of CPU load for the resampling is not something to be neglected. But with the right tools and configuration it can be reduced.
The USB audio gadget is a good example. We showed that the feedback functionality of the USB helps reduce the CPU usage. Others tasks could then run, or the setup complexity could be increased. The sample rate of the USB audio can be changed more easily than other devices. If needed, the USB host can perform resampling ahead of sending audio via USB, which frees up resources on the device.
Other techniques could be explored to reduce the usage of resampling. In our case, the i.MX8 board provides a hardware asynchronous sample rate converter. Resampling could be offloaded to this module instead of running on CPU.






