Permettre la Détection Temps Réel grâce à la Génération de Données LiDAR
Synthétiques
Cette série d’articles couvrira les éléments essentiels au déploiement d’un système de détection en temps réel avec un module dToF 3D LiDAR. Ce premier article est consacré à la génération de données LiDAR synthétiques.
L’intégration de modèles d’IA dans des plateformes embarquées permet désormais de nouveaux cas d’usage en vision par ordinateur, par exemple la robotique mobile ou la navigation autonome. Cependant, lorsque le système n’a pas accès à un flux RGB exploitable, e.g., dans des conditions de faible luminosité, il devient essentiel de s’appuyer sur des modalités de détection alternatives. L’exploitation des données de profondeur dToF et infrarouge garantit une détection robuste en temps réel pour les systèmes LiDAR embarqués.
En outre, un nouveau (à la date d’écriture de cet article en 2026) module embarqué dToF 3D LiDAR basse résolution, tels que le VL53L9CX, émerge comme une option particulièrement adaptée aux systèmes robotiques. Sa matrice 54 × 42 fournit simultanément des données de profondeur, d’intensité NIR et d’illumination active avec une empreinte énergétique minimale.
Ensuite, une architecture YOLO adaptée couplée à des données LiDAR brutes permet une perception en temps réel. L’implémentation matérielle devient un défi clé à ce stade. C’est pourquoi l’exploitation d’accélérateurs matériels tels que les NPU est essentielle. Cela garantira une détection en temps réel sur des systèmes LiDAR basse consommation.
Finalement, la qualité des données d’entraînement détermine directement les performances du modèle de détection. Cependant, collecter et annoter des données LiDAR même à basse résolution, est coûteux et difficile à mettre à l’échelle. Une alternative consiste en la génération de données LiDAR synthétiques. L’objectif est de permettre un prototypage rapide de la solution.
Génération de Données LiDAR Synthétiques pour la Détection en Temps Réel
Les jeux de données LiDAR existants proviennent principalement de capteurs 3D haute densité produisant des millions de points. Ceux-ci sont couramment utilisés dans la conduite autonome. De tels formats ne peuvent être ni capturés ni exploités sur des systèmes embarqués fortement contraints. En particulier dans notre cas, le matériel cible est le VL53L9CX, un LiDAR dToF produisant une matrice 2D de 54 × 42 pixels. Un entraînement adapté à nos contraintes nécessite donc des données de profondeur et d’infrarouge proche de la réponse NIR, à 940 nm, du capteur.
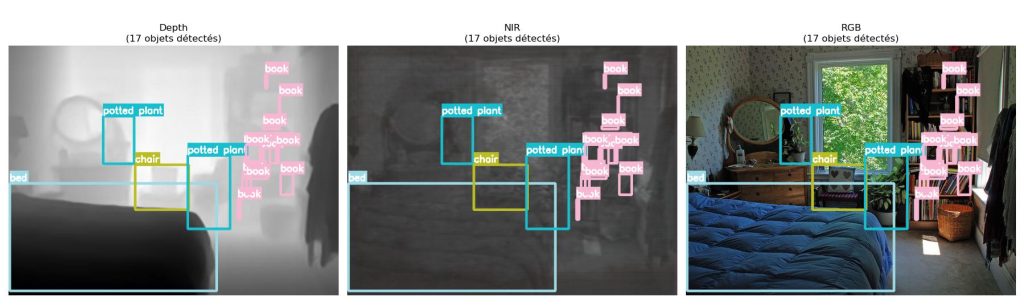
Cependant, collecter et annoter des données LiDAR à basse résolution reste un processus coûteux et lent. La génération de données LiDAR synthétiques est donc une approche efficace pour un entrainement de modèles d’IA. Parallèlement, les labels sont des éléments essentiels à la bonne exploitation des données générées. Ici, nous exploitons les labels du jeu de données COCO en ne convertissant que la modalité d’image : de RGB vers profondeur et NIR. En utilisant le jeu de données COCO, nous préservons les boîtes englobantes et les classes d’origine. La structure de la scène reste identique, seule la modalité change. La figure suivante illustre une image du jeu de données COCO en RGB original. En comparaison, la même image est traduite en modalités profondeur et NIR, avec les mêmes labels.
Implémentation Technique de la Génération Synthétique
Nous nous appuyons sur des modèles open-source spécialisés pour la génération de données LiDAR synthétiques :
Génération de Données NIR
Pix2Next est une extension de la famille de modèles Pix2Pix, en intégrant des Modèles de Fondation pour la Vision – Vision Foundation Models. Ces modèles servent d’extracteurs de caractéristiques. Ils utilisent l’attention croisée dans une architecture encodeur-décodeur. Cette approche améliore significativement la cohérence visuelle des images NIR synthétiques. Particulièrement dans des conditions de faible luminosité ou d’illumination partielle qui sont des régimes de fonctionnement typiques pour les capteurs dToF. Le diagramme suivant illustre l’architecture Pix2Next :
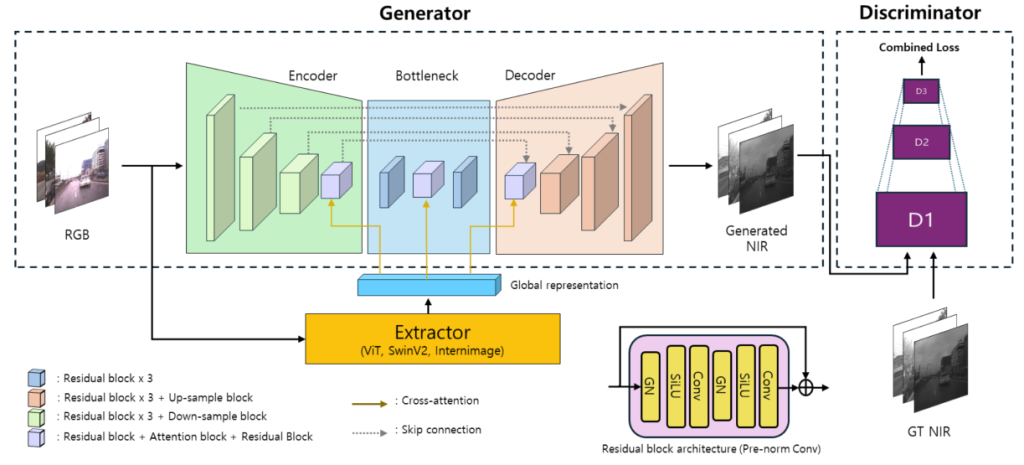
Il s’agit d’un réseau antagoniste génératif – Generative Adversarial Network (GAN) – conçu pour la traduction RGB vers NIR. Il se compose d’un générateur et d’un discriminateur. De plus, un extracteur de caractéristiques renforce la représentation globale. La compétition entre le générateur (qui tente de tromper) et le discriminateur (qui tente de détecter les faux) guide la génération d’images NIR de haute fidélité.
Détails de l’architecture Pix2Next :
Générateur : une architecture Encodeur–Goulot d’étranglement–Décodeur prend une image RGB en entrée et produit une image NIR en sortie. L’encodeur utilise des blocs résiduels et des couches de sous-échantillonnage. L’objectif est de réduire progressivement les dimensions spatiales tout en extrayant les caractéristiques essentielles. Ces caractéristiques compressées atteignent le goulot d’étranglement : trois blocs résiduels représentant l’image à sa résolution la plus basse. Le décodeur utilise ensuite des blocs résiduels et des couches de sur-échantillonnage pour restaurer la résolution spatiale.
L’attention croisée permet aux caractéristiques de l’encodeur et du décodeur d’interagir avec la représentation globale de la scène provenant de l’extracteur. Cela améliore grandement la cohérence de la sortie NIR finale.
Extracteur : capture la sémantique de haut niveau de l’entrée RGB en utilisant des architectures de vision puissantes telles que ViT, SwinV2 ou InternImage. Il produit une représentation globale qui agit comme un résumé sémantique de l’image. Cela améliore la qualité de la génération NIR.
Discriminateur : évalue le réalisme des images NIR générées en les comparant avec la vérité terrain NIR réelle. Il opère à plusieurs échelles (D1, D2, D3). Cela permet l’évaluation de la qualité de l’image depuis les détails fins (haute résolution) jusqu’aux structures globales (basse résolution).
Génération de données de profondeur
Nous utilisons deux modèles complémentaires :
ZoeDepth : estimation de profondeur absolue, directement corrélée à la distance capteur-objet.
DepthAnythingV2 : estimation de profondeur relative, décrivant la structure de la scène indépendamment de l’échelle.
ZoeDepth est une architecture conçue pour générer des cartes de profondeur absolue à partir d’une seule image RGB. La profondeur absolue est la distance réelle entre l’objet et la caméra. Elle répond à une limitation majeure des modèles classiques d’estimation de profondeur. En effet, elle fournit des mesures directement utilisables dans des applications critiques telles que la robotique ou la navigation autonome. Aperçu du modèle Zoe :
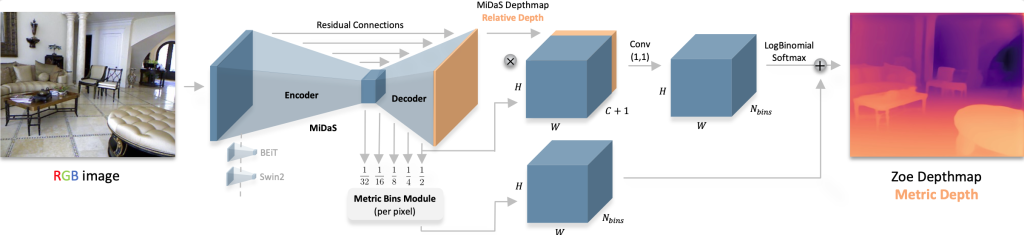
Son architecture comprend deux composants : (1) une structure encodeur-décodeur qui capture la profondeur relative, et (2) un module d’intervalles métriques – Metric Bins Module qui convertit celle-ci en profondeur absolue.
Détails de l’architecture Zoe :
Encodeur-décodeur : l’encodeur, basé sur des architectures puissantes telles que BEiT ou SwinV2, extrait les caractéristiques clés. Le décodeur reconstruit une carte de profondeur relative (ordre des objets : qui est devant), en utilisant des connexions résiduelles pour préserver la fidélité des détails.
Module d’intervalles métriques : au lieu de prédire une seule distance, le module estime pour chaque pixel une distribution de probabilité sur des intervalles de distance prédéfinis (intervalles). Cela fournit une référence pour l’échelle du monde réel. Il fusionne ensuite cette information avec des indices structurels de la carte de profondeur relative en utilisant la convolution et une fonction de sortie dédiée.
Bien que la profondeur absolue s’aligne mieux avec les exigences de navigation et d’évitement d’obstacles, la profondeur relative peut fournir de précieux indices structurels. L’objectif est d’évaluer si la combinaison de ces modalités améliore la robustesse et la généralisation, en particulier dans des environnements non vus.
Nettoyage du jeu de données : la génération de données LiDAR synthétiques pour la détection en temps réel peut conduire à certains échantillons inutilisables. Par exemple, des sorties complètement noires causées par des problèmes de normalisation lors du traitement ZoeDepth, un problème connu. Une étape de post-traitement filtre automatiquement ces échantillons pour garantir un jeu de données cohérent et utilisable.
Adaptation Finale du Jeu de Données : Classes et Cibles de Détection
Le jeu de données COCO contient 80 classes, dont beaucoup ne sont pas pertinentes pour certaines applications spécifiques (animaux, catégories alimentaires). Pour concentrer l’entraînement sur des catégories cohérentes pour nos applications, nous avons réduit les labels et généré deux jeux de données :
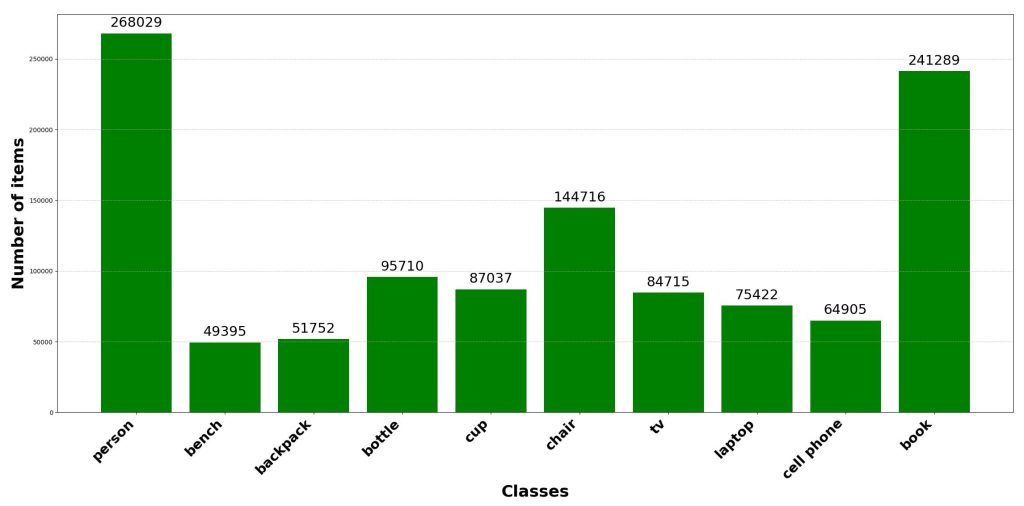
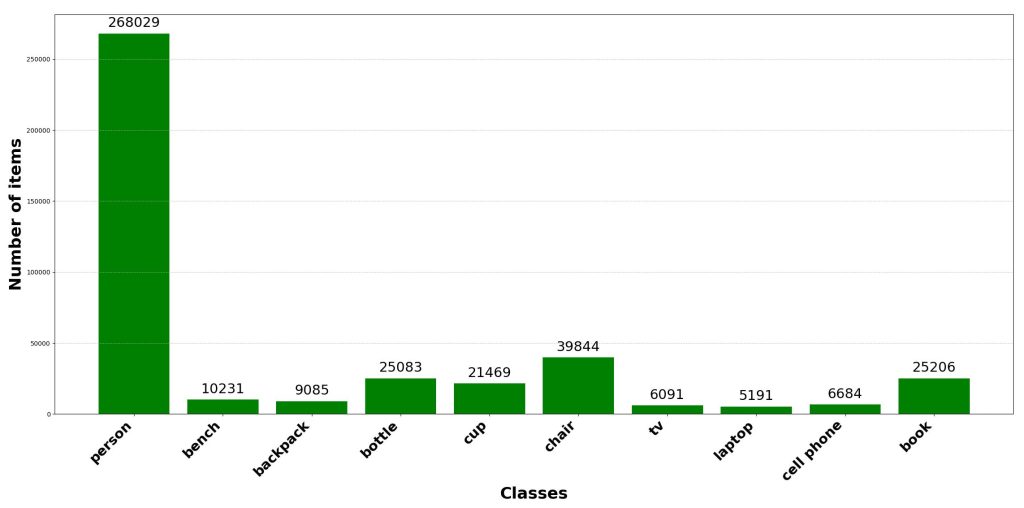
Jeu de données 10 classes : [personne ; banc ; sac à dos ; bouteille ; tasse ; chaise ; tv ; ordinateur portable ; téléphone portable ; livre]
Jeu de données classe unique : [personne]
L’équilibrage des classes est un facteur critique influençant les performances et la robustesse des modèles de vision par ordinateur. Les classes sous-représentées tendent à être ignorées pendant l’entraînement. La conséquence est le sur-apprentissage du modèle des classes dominantes. Ainsi, la capacité de généralisation est réduite. Assurer des données équilibrées lors d’une génération de données LiDAR synthétiques peut améliorer significativement le résultat des étapes suivantes. Par exemple, atténuer le déséquilibre par sur-échantillonnage, augmentation ciblée ou pondération de la perte, améliore la stabilité d’entraînement et les performances globales. Les deux figures suivantes illustrent le résultat de l’augmentation de données effectuée sur le jeu de données 10 classes, avec augmentation de données à gauche et sans à droite.
 |  |
Le prochain article de cette série, « Détection Temps Réel Système LiDAR : YOLO pour l’Edge AI », décrit l’exploitation de ces jeux de données synthétiques pour entraîner le modèle de détection d’objets YOLO.



