Enable Real-time Detection with Synthetic LiDAR Data Generation
This series of articles will cover the essential components required to build real-time detection on a system with a dToF 3D LiDAR module. This first article is focused on synthetic LiDAR data generation.
Integrating AI models into embedded platforms is now enabling new use cases in computer vision, e.g., mobile robotics or autonomous navigation. However, when the system does not have access to a usable RGB stream, i.e., low-light conditions, it becomes essential to rely on alternative sensing modalities. Leveraging dToF depth and infrared data ensures robust real-time detection for LiDAR edge systems.
Above all, a new (as of writing this article in 2026) low-resolution embedded dToF 3D LiDAR module, such as the VL53L9CX, is emerging as a highly suitable option for robotic systems. Its 54×42 array delivers simultaneous depth, NIR intensity, and active illumination data with a minimal power footprint.
An adapted YOLO architecture coupled with raw LiDAR data enables real-time perception for autonomous navigation and tracking. Hardware implementation becomes a key challenge at this stage. Leveraging hardware accelerators such as NPUs is essential to guarantee real-time detection with dToF 3D LiDAR module.
In addition, the quality of the training data directly determines the performance of the AI model. Yet collecting and annotating LiDAR data, even at low resolution, remains costly and difficult to scale. An alternative consists of synthetic LiDAR data generation, enabling rapid prototyping and the simulation of diverse environments.
Synthetic LiDAR Data Generation for Real-time Detection
Existing LiDAR datasets mainly come from high-density 3D sensors producing millions of points. These are commonly used in autonomous driving. Such formats cannot be captured nor exploited on highly constrained embedded systems. Especially in our case, the target hardware is the VL53L9CX, a dToF LiDAR outputting a 2D matrix of 54 × 42 pixels. Effective AI training demands depth and infrared data that physically replicate the sensor’s 940 nm NIR response.
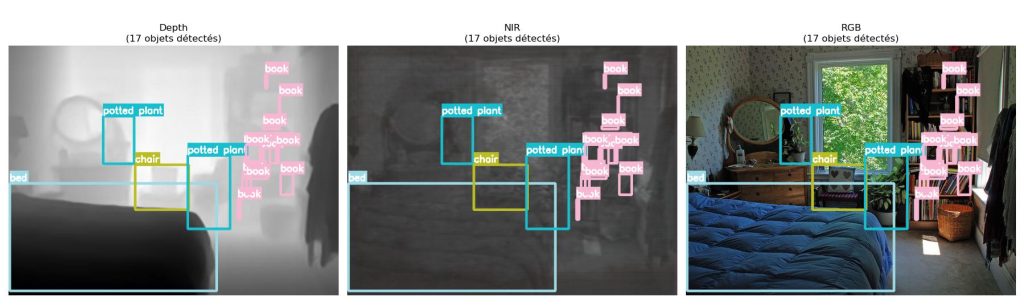
However, collecting and annotating LiDAR data, even at low resolution, remains a costly and slow process. Synthetic LiDAR data generation is therefore the most effective approach to enable training for real-time detection. At the same time, labels are essential elements for the effective use of the data generated. Our method leverages COCO dataset labels by converting only the image modality: from RGB to depth and NIR. By using the COCO dataset, we preserve the original bounding boxes and classes. Scene structure remains identical, only the modality changes. The following figure depicts an image from the COCO dataset in original RGB. In comparison, the same image is translated in depth and NIR modalities, with the same labels.
Technical Implementation of Synthetic Generation
We rely on specialized open-source models for synthetic LiDAR data generation:
NIR Data Generation
Pix2Next extends the Pix2Pix framework by integrating Vision Foundation Models. These models serve as feature extractors and use cross-attention within an encoder–decoder architecture. This approach significantly improves the fidelity and visual consistency of synthetic NIR images. Especially with low-light or partially illuminated conditions that are typical operating regimes for dToF sensors. The following diagram illustrates an overview of the Pix2Next architecture.
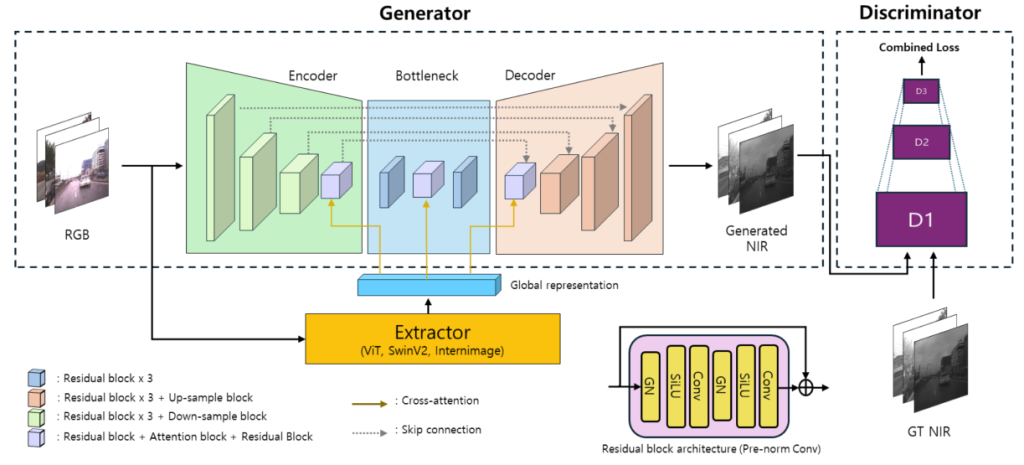
It is a generative adversarial network (GAN) designed for RGB-to-NIR translation. It consists of a generator and a discriminator, along with a feature extractor reinforcing global representation. The competition between the generator (trying to fool) and the discriminator (trying to detect fakes) drives the generation of high-fidelity NIR images.
Generator: an Encoder–Bottleneck–Decoder architecture that takes an RGB image as input and outputs an NIR image. The encoder uses residual blocks and down-sampling layers to progressively reduce spatial dimensions while extracting essential features. These compressed features reach the bottleneck: three residual blocks representing the image at its lowest resolution. The decoder then uses residual blocks and up-sampling layers to restore spatial resolution.
Cross-attention lets encoder and decoder features interact with the global scene representation from the extractor. It greatly improves the consistency in the final NIR output.
Extractor: captures high-level semantics from the RGB input using powerful vision architectures such as ViT, SwinV2, or InternImage. It produces a global representation that acts as a semantic summary of the image, enhancing NIR generation quality.
Discriminator: evaluates the realism of generated NIR images by comparing them with real NIR ground truth. It operates across multiple scales (D1, D2, D3). It enables the assessment of image quality from fine details (high resolution) to global structures (low resolution).
Depth Data Generation
We use two complementary models:
ZoeDepth: absolute depth estimation, directly correlated with sensor–object distance.
DepthAnythingV2: relative depth estimation, describing scene structure independent of scale.
ZoeDepth is an architecture designed to generate absolute depth maps from a single RGB image. The absolute depth is the actual distance between the object and the camera. It addresses a major limitation of classical depth estimation models. Indeed, it provides measurements directly usable in critical applications such as robotics or autonomous navigation. Overview of Zoe model:
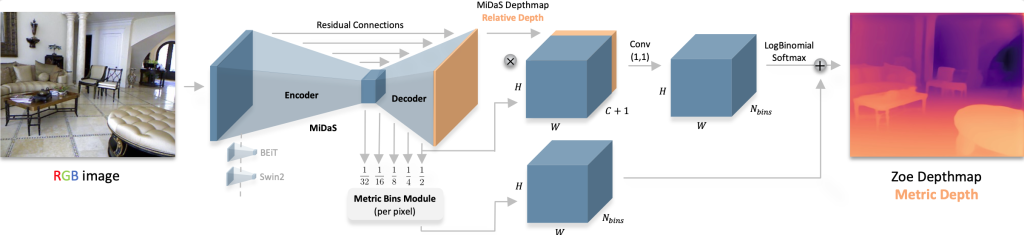
Its architecture includes two components: (1) an encoder–decoder structure that captures relative depth, and (2) a Metric Bins Module that converts this into absolute depth.
Encoder–decoder: the encoder, based on powerful backbones such as BEiT or SwinV2, extracts key features. The decoder reconstructs a relative depth map (object ordering: who is in front), using residual connections to preserve detail fidelity.
Metric Bins Module: instead of predicting a single distance, the module estimates, for each pixel, a probability distribution across predefined distance intervals (bins). This provides a reference for real-world scale. It then fuses this information with structural cues from the relative depth map using convolution and a dedicated output function.
While absolute depth aligns better with navigation and obstacle avoidance requirements, relative depth can provide valuable structural cues. The objective is to evaluate whether combining these modalities enhances robustness and generalization, especially in unseen environments.
Dataset cleaning: synthetic LiDAR data generation for real-time detection can lead to some unusable samples. For instance, completely black outputs are caused by normalization issues during ZoeDepth processing, a known problem. A post-processing stage automatically filters out such samples to ensure a consistent and usable dataset.
Final Dataset Adaptation: Classes and Detection Targets
The COCO dataset contains 80 classes, many of which are not relevant for certain specific applications (animals, food categories). To focus the training on meaningful categories, we reduced the label space and generated two datasets:
10-class dataset: [person; bench; backpack; bottle; cup; chair; tv; laptop; cell phone; book]
Single-class dataset: [person]
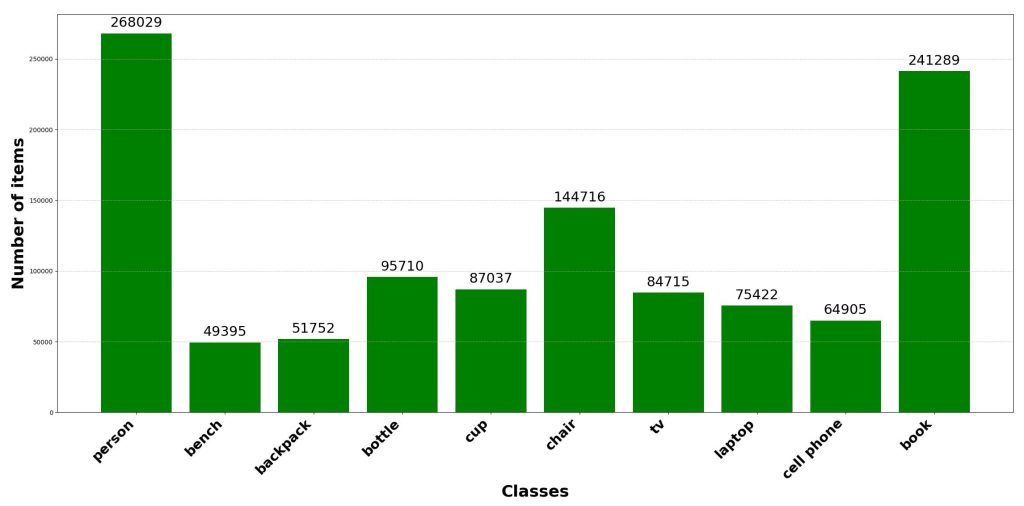
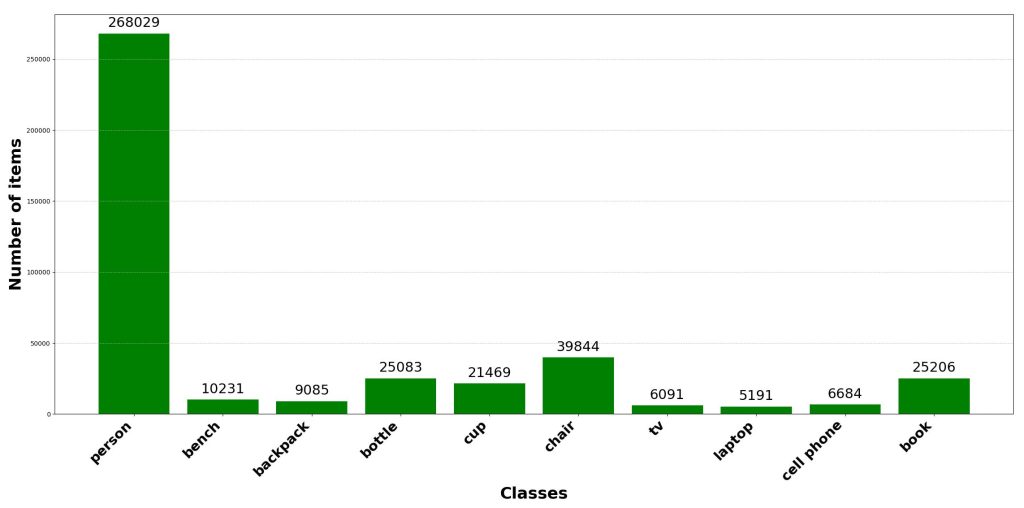
Class balance is a critical factor influencing the performance and robustness of computer vision models. Underrepresented classes tend to be ignored during training, leading the model to overfit dominant classes and reducing generalization. Ensuring balanced data during synthetic LiDAR data generation can significantly improve the output of the next steps. For instance, mitigating imbalance through oversampling, targeted augmentation, or loss weighting improves training stability and overall performance. The following two figures illustrate the result of the data augmentation performed on the 10-class dataset, with data augmentation on the left and without on the right.
The next article in this series, “Real-time Detection on a LiDAR System: Training YOLO for Edge AI”, will explore how to best leverage these synthetic datasets to train the YOLO object detection model.