Deploying a Convolutional Neural Network on an Embedded System
Introduction
The rise of embedded platforms capable of AI processing has been a real game changer: it is now possible to deploy intelligent solutions directly on the device itself, without relying on the cloud. This is known as « edge AI ».
In a recent project, we explored how to deploy a real-time object detection system using a computer vision model on a Verdin NXP i.MX 8M Plus board, a popular target thanks to its integrated Neural Processing Unit (NPU).
This article shares our technical experience: from model conversion to integration into a Yocto image, including the trade-offs needed to achieve real-time performance with satisfactory results.
Context and Objective
ICOR Technology designs and manufactures high-quality, innovative, and cost-effective robots, tools, and equipment for EOD and SWAT communities worldwide. Users can remotely operate ICOR robots through a Command and Control Unit, which displays real-time video feeds from the robot’s cameras.
The project aimed to develop a demonstration of vision-assisted robotic navigation powered by a real-time object detection model as illustrated in the picture below.
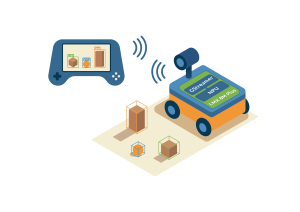
The main objectives were:
- Processing at 30 frames per second
- Execution on a low-power embedded target
- Use of a pre-trained model of type YOLOv8 (You Only Look Once)
- Generic object detection (people, chairs, etc.), face detection, and navigation elements detection (doors, stairs, windows)
- Full integration into a Linux Yocto image
We chose to work with the System on Module (SoM) Verdin i.MX 8M Plus, which combines CPU, GPU, VPU, and NPU in a format suited for industrial applications.
Hardware Platform
The Verdin NXP i.MX 8M Plus, co-developed by NXP and integrated on a board designed by Toradex, offers a good balance for embedded AI processing:

- CPU: 4 Cortex-A53 cores at 1.8 GHz
- GPU: up to 16 GFLOPS
- NPU: up to 2.3 TOP/s
- VPU: hardware video encoder/decoder (H.264/H.265)
This hardware accelerates AI inference while respecting the constraints of footprint, thermal dissipation, and power consumption of embedded systems.
TensorFlow and TensorFlow Lite

TensorFlow is an open-source library developed by Google, widely used in the fields of machine learning and artificial intelligence. It provides a complete infrastructure for training and deploying neural network models, with a large ecosystem of tools and resources that make it a reference for both research and industry.
TensorFlow Lite (TFLite) is a variant of TensorFlow specifically designed for constrained environments such as embedded systems and mobile devices. It enables optimized models to run by reducing their size and resource consumption, while taking advantage of hardware accelerators (GPU, NPU, DSP).
Yocto

Yocto Project is an open-source project that provides a set of tools, scripts, and layers to build customized embedded Linux systems. Yocto allows you to generate an image tailored to the specific needs of a given hardware, keeping only the necessary components. This makes it a reference tool for constrained environments, where optimization of size, performance, and security is essential.
Integrating TensorFlow Lite into Yocto
While flexible, the Yocto environment requires careful configuration to support Machine Learning libraries. Here are the key steps we followed:
- Base BSP Toradex: provided for the SoM used
- Add the meta-imx-ml layer: it provides the recipes for
tensorflow-lite, etc. - Required dependencies:
opencv, python3-numpy, etc. - Image configuration: include necessary packages in
local.conf or a .bbappend file - Conflict resolution: Yocto layers for AI are not always aligned; some integration work is required
Indeed, in embedded systems, package versions are fixed. However, some packages may share dependencies but with different versions, which must then be resolved.
Model Conversion and Quantization
The detection model used, YOLOv8, was trained with Ultralytics. We chose YOLOv8 because it was a state-of-the-art architecture when we started this project. Developed under PyTorch, it was then converted into a TensorFlow Lite model to be compatible with the i.MX 8M Plus NPU. The version we used was the Nano, the lightest in the range, selected to meet the real-time constraint.
Conversion steps:
- Conversion
.pt (PyTorch) → .onnx (Open Neural Network Exchange) → .tflite(TensorFlow Lite) - Quantization in int8 for compatibility: quantization reduces the memory footprint of models and significantly speeds up their execution, while ensuring their compatibility with the NPU.
- Some operations of the original model not being supported in the TFLite format, we had to manually implement the preprocessing and postprocessing steps, notably Non-Maximum Suppression (NMS) as shown in the picture below.
The neural network produces multiple potential detections for the same object. The Non-Maximum Suppression (NMS) algorithm reviews these proposals and keeps the one with the highest confidence score while removing duplicates.
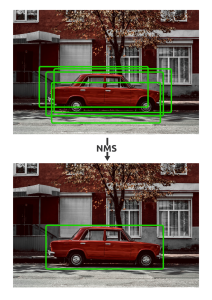
💡 The i.MX 8M Plus NPU only accepts fully quantized (full integer) models. It is therefore necessary to calibrate the models to ensure their execution on the hardware accelerator.
Multi-Network Strategy and Resolution Selection
Our application had to cover three distinct detection tasks:
- Generic object detection with the COCO dataset
- Detection of navigation elements (doors, stairs, windows) using a specific dataset
- Face detection using a facial identification dataset
A first centralized approach…
At first, we tried to train a single network combining the three datasets. This approach, while appealing on paper, quickly showed its limits in terms of performance. The reasons are multiple:
- Inconsistencies in annotation conventions between datasets
- Heterogeneous nature of the images (indoor scenes, faces, everyday objects)
- Imbalance in label distribution, with some being largely underrepresented
Below we can see:
- an example image from the COCO segmentation dataset with its annotation : the objects pixels are colored within their contour.
- a montage of several images from the face dataset: one face is one image from the dataset et its annotation is the entire image.


Towards a specialized multi-network approach
To overcome these limitations, we opted for a more modular solution: a separate neural network for each task, each optimized with an appropriate resolution. This was an audacious approach, since running three distinct neural networks on a resource-constrained embedded system is a real technical challenge. And yet we succeeded in making it work effectively in real time. Interestingly, this design also echoes the concept of a Mixture of Experts architecture, where different specialized models contribute to solving different aspects of a problem. There are the dimensions we chose for the different dataset:
- COCO: quantized network at 320×320
- Navigation (doors, stairs, windows): 160×160
- Faces: also at 160×160
This choice allowed us to obtain very satisfactory results while reducing computational load. The following table and graph summarizes the measured performance for each configuration.
Performance Results
| Resolution | Time (ms/image) | Estimated FPS | Precision | Rappel | F1-score |
|---|
| 640×640 | 58 ms | 17.2 fps | 89.5% | 28.2% | 0.429 |
| 480×480 | 34 ms | 29.4 fps | 90.6% | 25.7% | 0.400 |
| 320×320 | 15.5 ms | 64.5 fps | 91.5% | 20.7% | 0.338 |
| 160×160 | 5.3 ms | 188.7 fps | 90.6% | 10.0% | 0.180 |
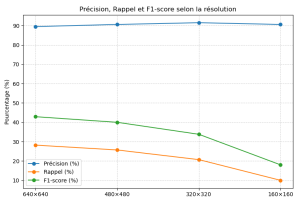
As shown in the table and on the graph, lower resolutions allow ultra-fast processing (low inference time or high FPS), making them ideal for networks specialized in specific tasks, where the loss of accuracy remains acceptable.
Conclusion
In this project, we integrated TensorFlow Lite into Yocto while resolving dependency conflicts, explored a multi-network approach to specialize detection tasks, and adjusted resolution to find the best balance between speed and accuracy. We did not just deploy a single model, but successfully ran three specialized neural networks on a resource-constrained embedded system in real time (30 fps), showing the potential of real-world embedded AI.
This experience demonstrates that embedded intelligent vision solutions are accessible today, even on resource-constrained platforms, provided the tools are well mastered, from AI frameworks to Yocto layers.
We believe that this type of integration between embedded Linux systems and AI represents a promising path for the future of automation, robotics, and industry in general.






