Monocular Depth Estimation on the Verdin i.MX95 for Edge AI
Deploying Monocular Depth Estimation on the Verdin i.MX95 for Edge AI: model adaptation, INT8 quantization, and a full embedded software stack for real-time depth inference at 30 FPS from a single RGB camera.
Monocular depth estimation involves reconstructing a depth map from a single image captured by an RGB camera. In this article, we demonstrate the deployment of monocular depth estimation on the Verdin i.MX95. We based our approach on the MiDaS depth estimation model on the NXP i.MX 95 processor, accelerating performance from 7 FPS on the CPU to 30 FPS on the Neutron NPU to achieve real-time inference on a Toradex Verdin iMX95 System on Module. We cover the full engineering path from the model adaptation for NPU compatibility to the post-training quantization, NPU compilation, GStreamer pipeline integration, and Yocto image assembly.
This demo was presented at Embedded World 2026 to highlight Savoir-faire Linux’s Edge AI engineering services, showcasing our long-standing partnership with Toradex in embedded software development.
Why Monocular Depth Estimation at the Edge?
Depth perception is foundational for robotics, autonomous navigation, and industrial inspection. Traditional approaches rely on stereo cameras or LiDAR, which add cost, power draw, and calibration complexity. Monocular depth estimation eliminates this by inferring depth from a single camera, a sensor that is already present in most embedded platforms.
However, the AI models behind this capability are computationally intensive. Running them on a general-purpose CPU at video rates is impractical on most edge hardware. The Neutron engine in the NXP i.MX95 changes this equation. It delivers the throughput required for model inference while operating within a few watts of power.
The Toradex Verdin i.MX95 system-on-module, pin-compatible with the Verdin ecosystem and paired with the Verdin Development Board, provides an ideal platform for this project. It combines the Neutron NPU at 2 TOPS with a highly energy-efficient Cortex-A55 cluster.
Our objective was to demonstrate that a complete, end-to-end monocular depth estimation pipeline could run entirely on this module at 30 FPS.
Toradex Verdin i.MX95 module
Complete Setup: Verdin Development Board, Verdin iMX95 System on Module and CSI camera (OV5640)
Choosing the Right Model: MiDaS v2.1 Small
We selected the AI model MiDaS v2.1 256 from the Intel ISL MiDaS family. It uses an EfficientNet-Lite3 encoder and a four-stage RefineNet decoder with an expanding feature scheme (64 → 128 → 256 → 512 channels). The input resolution is 256×256, and the output is a single-channel inverse relative depth map at the same resolution.
Despite being optimized for embedded deployment, the model still demands substantial computational resources, achieving a mere 7 FPS on the CPU. This motivated our in-depth exploration into leveraging the hardware acceleration capabilities of the Neutron NPU.
Adapting the Model for the Neutron NPU
Deploying a PyTorch model on a dedicated NPU is not a matter of simple format conversion. Certain operations that work well on CPUs and GPUs may not be supported by NPU hardware.
The adaptation we performed on the AI model was the replacement of all bilinear interpolation with nearest neighbor interpolation. Leaving these operations unchanged would force 5 fallbacks to CPU execution, severely impacting throughput.
We compared float32 depth maps between the original (bilinear) and adapted (nearest) models on COCO images. Validation conducted on a 1,000-image validation set yielded a minimum Pearson correlation of 0.954, with an average of 0.997. The depth maps are structurally near identical. Differences concentrate at object boundaries where bilinear smoothing produces slightly softer edges, an acceptable trade-off for full NPU execution.
Quantization and NPU Compilation
We used the eIQ Neutron SDK v3.0.0 for the full conversion pipeline. This is a three-step process applied on the Edge AI model: profiling, quantization, and NPU compilation.
Step 1: ONNX Export and TFLite Conversion. The adapted PyTorch model is exported to ONNX (opset 17, static shape). The ONNX model is then converted to TFLite float32 via the ONNX-TF bridge, with NHWC input layout.
Step 2: The “neutron-profiler” tool runs the float32 model on calibration dataset (COCO images with ImageNet normalization) to collect per-tensor activation histograms. These histograms drive the neutron-quantizer, which applies full INT8 post-training quantization per tensor.
Step 3: NPU Compilation. The neutron-converter tool compiles the INT8 model into a TFLite file with embedded Neutron microcode. This step performs graph-level optimization, Neutron subgraph extraction, tile scheduling, TCM (Tightly Coupled Memory) allocation, and microcode generation.
NPU Compilation Results
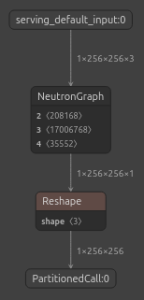
The Neutron compiler achieved a 99.45% operator conversion ratio: 181 out of 182 operators run natively on the NPU, packed into a single monolithic Neutron subgraph. This means the NPU executes the entire inference graph as one contiguous kernel call, minimizing CPU–NPU data transfer overhead.
MiDaS v2.1 Small compiled into a single monolithic Neutron subgraph
NPU compilation results for MiDaS v2.1 Small 256
Metric
Value
Operators of the AI model
182
Operators on NPU
181
Operators on CPU (fallback)
1
Conversion ratio
99.45%
Neutron subgraphs
1
Estimated latency (@ 1 GHz)
11.58 ms
The single non-converted operator is a trivial reshape at the output boundary, adding microseconds of CPU overhead per inference.
Model memory size after compilation process
Stage
Format
Size
TFLite float32
float32
64 MB
TFLite INT8 (quantized)
INT8
17 MB
TFLite + Neutron (NPU-compiled)
INT8 + microcode
17 MB
The quantization step achieves a 3.8× size reduction from float32 tflite. The Neutron compilation does not significantly change file size because the NPU microcode and weight buffers are comparable in volume to the original INT8 data.
Building the Real-Time Pipeline
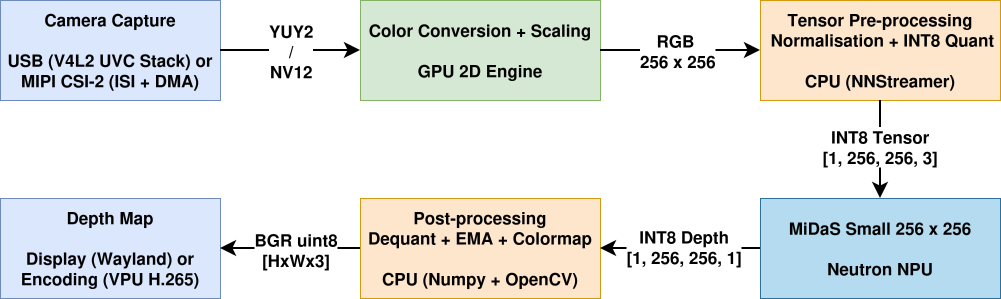
An Edge AI model running on the NPU in isolation is not a product. We built a complete GStreamer pipeline to handle the full data path from camera capture to visual output.
Pipeline Architecture
The Edge AI system uses a three-layer architecture:
GStreamer/NNStreamer preprocessing: camera capture (USB or CSI), hardware-accelerated color-space conversion via the GPU 2D engine, scaling to 256×256, and ImageNet normalization with INT8 quantization via NNStreamer.
Python inference thread: preprocessed INT8 tensors are pulled from a GStreamer appsink into a dedicated inference thread that runs the tflite interpreter with the Neutron delegate.
Post-processing and output: the raw INT8 depth tensor is dequantized, smoothed via temporal EMA (α=0.4), filtering, normalized with percentile clipping (value of 5, to eliminate outlier-driven flicker), and colorized with the inferno colormap. Output sinks include an MJPEG HTTP server, Wayland display, and MP4 recording via the VPU hardware encoder.
Pipeline Architecture
Hardware Elements used
Stage
Hardware
Camera capture
USB (V4L2 UVC Stack) / MIPI CSI-2 (ISI + DMA)
Color conversion + scaling
GPU 2D engine
Tensor pre-processing
CPU (NNStreamer)
Depth inference
Neutron NPU
Post-processing
CPU (NumPy + OpenCV)
Video encoding (record mode)
VPU (H.265)
Why Not NNStreamer’s tensor_filter?
NNStreamer provides a “tensor_filter” element designed exactly for this use case, running TFLite inference inside a GStreamer pipeline. We initially implemented this approach, but encountered a critical issue: “tensor_filter” loads the Neutron delegate correctly but returns incorrect output tensors (nearly featureless depth maps). The same preprocessed input, when fed to Python “tflite_runtime” with the same delegate, produces correct depth maps. While less elegant from a GStreamer-purity standpoint, it provides correct results and thanks to the threaded decoupling, does not introduce a performance bottleneck.
Yocto Integration: From Model to Flashable Image
The entire software stack was initially assembled into a flashable Linux image using the Yocto Project (Walnascar release) with the kas build orchestrator, utilizing a custom meta-layer to encapsulate our project-specific configurations.
To obtain TFLite 2.19 and the Neutron delegate, we selectively included only “meta-imx-ml” while excluding “meta-imx-bsp” to avoid conflicts with Toradex’s own BSP layer. The “meta-imx-bsp” is NXP’s reference BSP layer. When active, it unconditionally sets global assignments that redirect “virtual/kernel” to NXP’s own kernel fork and “virtual/bootloader” to NXP’s own U-Boot fork. Conversely, Toradex’s layers (“meta-toradex-nxp”, “meta-toradex-bsp-common”) provide their own forks which carry Verdin-specific patches, carrier-board device trees, and SOM init sequences. Finally, “meta-imx-ml” contains only ML library recipes like TFLite 2.19 and the Neutron / Ethos-U / VX delegates, with no kernel, bootloader, or machine configuration whatsoever. Because its only layer dependencies are “core” and “freescale-layer”, so it can be added on top of any BSP without conflict.
This mixing required targeted workarounds via bbappend files, patching ATF recipes, pinning U-Boot revisions, and adjusting QA checks for OpenCV. The image recipe assembles a comprehensive stack: GStreamer (base + good + bad + ugly), NNStreamer (core + TFLite + Python3), ML runtimes (TFLite 2.19 + Neutron delegate), OpenCV, Python packages, Weston compositor, and the depth estimation application scripts and models.
Results and Performance
Moving from a constrained ~7 FPS on the CPU, the final solution deployed on the Toradex Verdin iMX95 System on Module with the Verdin Development Board achieves ~30 FPS end-to-end depth estimation on the Neutron NPU, using both USB and CSI (OV5640) cameras.
The end-to-end FPS is measured by timestamping each produced frame across the full pipeline: camera capture, GPU-accelerated color conversion and scaling, tensor preprocessing, model inference, post-processing (dequantization, EMA smoothing, colormap), and Wayland display rendering. The CPU baseline runs the INT8 quantized MiDaS model via NNStreamer’s tensor_filter with the XNNPACK delegate, achieving ~7 FPS. The NPU configuration runs the same model compiled for the Neutron NPU, executing 99.45% of operations on the accelerator, achieving ~30 FPS, +330% improvement.
Per-stage latency is profiled using time.perf_counter() instrumentation. Two code paths exist depending on the backend. With the NPU, inference bypasses NNStreamer and is executed in Python via tflite_runtime with the Neutron delegate. A dedicated thread measures buffer extraction, invoke(), post-processing, and display independently. With the CPU, inference runs natively in C++ inside NNStreamer’s tensor_filter. Since it completes before the Python callback fires, inference time is estimated as capture_interval − callback_total, where capture_interval is the wall-clock time between consecutive tensor sink emissions and callback_total is the measured Python post-processing time. All metrics are averaged over 100-frame windows to smooth scheduling jitter.
Latency measurements between the NPU and the CPU pipeline
Measured Stages
NPU Pipeline (ms)
CPU Pipeline (ms)
Pre-processing
0.4
0.3
Inference
~10.9
~110
Postprocessing
8.7
7.3
Display
~13.1
~12.2
End-to-end FPS
~30 FPS
~7 FPS
Video demonstration of Monocular Depth Estimation running on Verdin iMX95
Key Engineering Takeaways
Deploying a depth estimation model on an NPU is not plug-and-play. Several lessons emerged from this project:
Operator compatibility drives model adaptation. A single unsupported operation (bilinear interpolation) would have forced significant CPU fallbacks. Systematic validation of the substitution against quality thresholds was essential.
Calibration normalization must match inference normalization exactly. This seems obvious in hindsight, but a mismatch was one of three bugs that produced incorrect depth maps during development.
NNStreamer with the Neutron delegate produced incorrect results, requiring a Python-based inference bypass. Close-to-hardware debugging was necessary.
A single-subgraph NPU execution pattern is the goal. Achieving 99.45% operator conversion with a single Neutron subgraph eliminates CPU–NPU transfer overhead during inference. This required both model adaptation and careful format control.
The full stack matters: model accuracy is meaningless without the surrounding pipeline, camera drivers, hardware-accelerated preprocessing, buffer management, and a build system that reliably assembles all dependencies.
Conclusion
We demonstrated that real-time monocular depth estimation is achievable on the Toradex Verdin iMX95 using the MiDaS v2.1 Small model. Monocular depth estimation on low-power hardware serves applications where LiDAR or stereo rigs are too costly, heavy, or fragile, such as AMR/warehouse navigation, agricultural obstacle avoidance in dust/sunlight and industrial inspection to separate defects from background. The common value proposition is replacing dedicated depth sensors with a software stack on a commodity camera and a low-power edge SoC.
The path from a PyTorch model to a 30 FPS embedded application required deliberate engineering at every layer: model adaptation for NPU operator compatibility, INT8 post-training quantization via the eIQ Neutron SDK, GStreamer pipeline design with hardware-accelerated preprocessing, and a Yocto-based build system that integrates Toradex BSP layers with NXP ML runtimes.
The result is a complete, reproducible embedded AI stack, from source code to flashable image, that transforms a single camera feed into a real-time depth map on a power-efficient edge platform. This work was demonstrated at Embedded World 2026 running on a Toradex Verdin i.MX95 module.
Live demonstrations at Booth 4-642 (Hall 4) will showcase real-time AI vision pipelines optimized for embedded hardware accelerators and built on the open-source AI ecosystem. Nuremberg, Germany, March 6, 2026 – Savoir-faire Linux, a leading open-source software engineering and consulting firm specializing in embedded and industrial systems, announces at Embedded World 2026 the official launch […]
Optimizing YOLO Training for Real-Time Detection on a LiDAR system This is the second of a three-part series on real-time YOLO detection on a LiDAR system for Edge AI. Find Article 1 on generating synthetic depth and NIR datasets here. Currently, new low-resolution embedded LiDAR such as the VL53L9CX, are emerging as a highly suitable […]
Enable Real-time Detection with Synthetic LiDAR Data Generation This series of articles will cover the essential components required to build real-time detection on a system with a dToF 3D LiDAR module. This first article is focused on synthetic LiDAR data generation. Synthetic LiDAR data generation for real-time detection Real-time Detection on a LiDAR System: Training […]