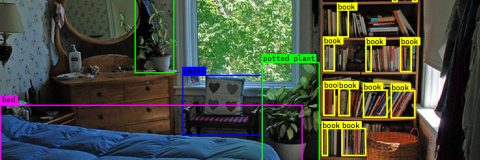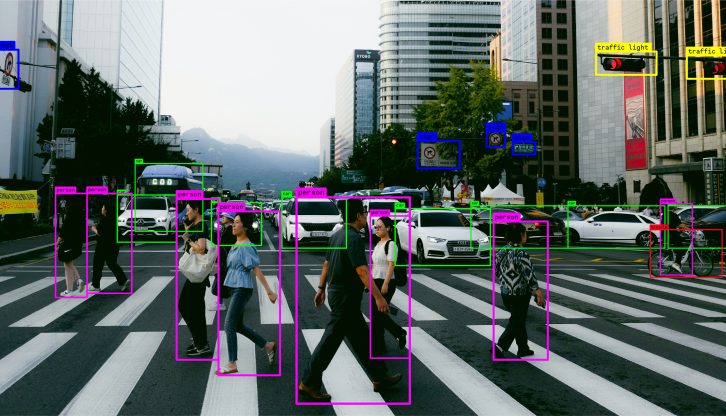
Démonstrations en direct au stand 4-642 (Hall 4) pour présenter des pipelines de vision par ordinateur avec l’IA en temps réel, optimisés pour les accélérateurs matériels embarqués et construits sur l’écosystème open source de l’IA. Nuremberg, Allemagne, le 6 mars 2026 – Savoir-faire Linux, une société leader dans le domaine de l’ingénierie logicielle open […]

6 Mar. 2026 Lecture de 5 minutes.